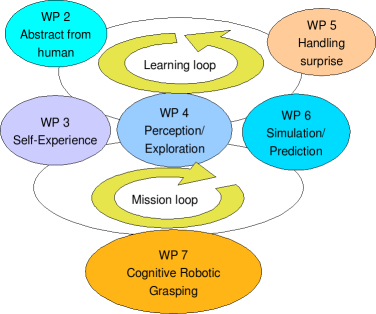
As shown in the above figure, the robot acquires initial models of actions and affordances of objects through interaction with human which triggers self-reasoning that provides additional attributes for objects that cannot be retrieved directly from the interaction with humans. These attributes are preferred alignments in the sensor data during the manipulation, e.g., a fixed orientation during a motion or a variation in the applied force. The robot also needs to decide the feasibility of performing the observed action by itself, using a simulation task that explains the presented motion with a set of basic motion primitives. The learning of a new motion- or force-attribute is triggered by ‘surprise-events and curiosity’ in a perception module from unexpected changes in the environment. The learned object attributes define a basic motion from A to B, which needs to be registered to the actual 3D structure of the world (background model). The basic motions will be merged to a task description, which defines the variability of their order. The ‘drive’ to perform a specific task is based on human guidance or reasoning about the current context.