
 Upp till Granskas startsida.
Upp till Granskas startsida.
Granska ser ut som ett vanligt ordbehandlingsprogram med de bekanta menynamnen Arkiv, Redigera, Format, Verktyg och Hjälp. Liksom i andra ordbehandlingsprogram har användaren tillgång till grundläggande ordbehandlingsfunktioner: skriva, redigera, formatera och spara text. Utöver detta finns en språkgranskningsfunktion, ett hjälpsystem med skrivregler och möjlighet till sökning på ordklasser.
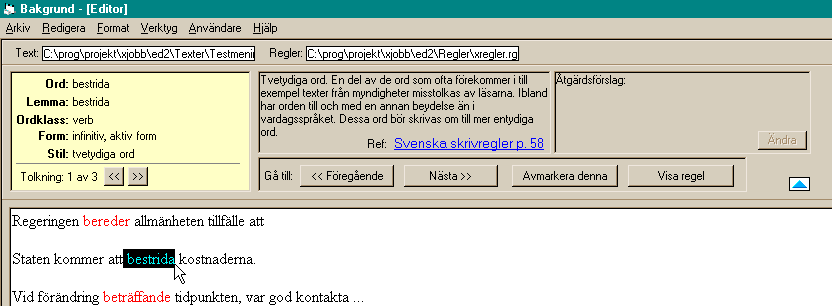
Granskningsfunktionen aktiveras på begäran av användaren, genom att denne väljer granskningskommandot i menyn. Fel och andra problem i texten markeras med olika färgkoder för olika klasser av fel (rött för grammatik-, stil-, och teckenfel, grönt för stavfel). Presentationen av fel går till så att en särskild granskningspanel (fig. 1) visas i övre delen av textfönstret. Granskningspanelen innehåller information om markerat ord, kommentarer, och åtgärdsförslag till felet, samt knappar för att gå till nästa respektive föregående fel i texten. Användaren kan också gå till vilket ställe i texten som helst genom att klicka i texten med musen eller använda någon av manövertangenterna på tangentbordet.
Så länge granskningsfunktionen är aktiv, fortsätter granskningen kontinuerligt medan användaren skriver och gör ändringar i texten.
Det vore en enkel uppgift att tagga text om det inte vore så att de flesta ord i en text kan tolkas på olika sätt; ett exempel är ordet för som kan vara både preposition, substantiv och verb. I nuvarande version av Granska löses problemet med flertydighet genom att alla ord i texten taggas med alla kända taggar för respektive ord. För varje regel måste antingen alla tolkningar av en ordsekvens matcha eller också räcker det med att bara en tolkning matchar. I det första fallet missar Granska många fel och i det andra ger Granska för många falska alarm. Genom att istället försöka hitta de mest sannolika tolkningarna av tvetydiga ordsekvenser hoppas vi att Granska ska hitta fler fel och ge färre falska alarm.
Om man analyserar en redan taggad träningstext och räknar hur många gånger varje ord taggats med olika taggar kan man göra en naiv gissning av taggningen för varje ord, nämligen den vanligaste taggen för just det ordet. Men nya Granska gör något mycket mer komplicerat genom att dessutom föra statistik på alla sekvenser av två och tre taggar i träningstexten. Med en s.k. Markovmodell kan sedan de sannolikaste taggningarna beräknas. Med naiv taggning blir under 90 procent av taggningarna rätt, men med en andra ordningens Markovmodell blir mer än 95 procent rätt.
Ett annat problem som försvårar taggning är att svenska språket innehåller så många ord och nya ord konstrueras kontinuerligt genom sammansättningar. Bara en del av alla svenska ord finns i den träningstext vi har. Följden blir att när taggaren ska tagga en text kommer den att stöta på okända ord som måste taggas. Genom att kombinera informationen om vilka taggsekvenser som är vanliga med en morfologisk analys av ordet kan rätt tagg gissas med ganska stor precision. Den morfologiska analysen bygger också på statistik. Nya ord taggas med sådana taggar som är sannolika för andra ord om slutar på samma bokstäver. Om ordet puddingarna är okänt för taggaren gissar den sannolikt att det är ett substantiv i plural eftersom det är den statistiskt sett vanligaste taggen för ord som slutar på -arna.
http://www.nada.kth.se/theory/projects/granska/
Upp till Granskas startsida.