
Föreläsning 9 - Automater, textsökning, KMP
AutomaterEn portkodsautomat med nio knappar kan se ut så här:A B C D E F G H I Anta att den rätta knappföljden är DEG. Då har automaten fyra olika tillstånd:
Man kan också rita en graf med fyra noder (som representerar tillstånden) och en massa bokstavsmärkta pilar (som visar vilka övergångar som finns). Här är några fler exempel på vad automater kan användas till:
TextsökningSamma automat kan användas för textsökning, till exempel för att söka efter GUD i bibeln. Bokstav efter bokstav läses och automaten övergår i olika tillstånd. När fjärde tillståndet uppnås har man funnit GUD. Datalogins fader, Donald Knuth, uppfann en enkel metod att konstruera och beskriva automaten. En Knuth-automat har bara en framåtpil och en bakåtpil från varje tillstånd. Så här blir den: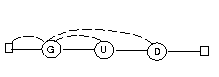 Ett nolltillstånd har skjutits in längst till vänster. Automaten startar emellertid i tillstånd 1, som har ett G i noden. Den tjuvtittar på första bokstaven i bibeln, och om det är ett G läser den G-et och går till höger. Annars följer den bakåtpilen utan att glufsa bokstaven. I nolltillståndet glufsar den alltid en bokstav och går till höger. Koden blir i princip så här, om vi först antar att bokstäverna lästs in i en kö:
i=1 # starttillståndet
while i<4:
if i==0 or q.peek()==gud[i]:
i=i+1
q.get()
else: i=next[i];
Här är gud[i] i-te bokstaven i det sökta ordet och
next[i] det tillstånd man backar till från
tillstånd i. Nextvektorn (bakåtpilarna) i vårt exempel blir
i next[i] 1 0 2 1 3 1Om vi i stället söker efter ADAM i bibeln blir Knuth-automaten så här: 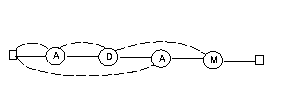 Nextvektorn för ADAM blir alltså den här: i next[i] 1 0 2 1 3 0 4 2För GUD gick bakåtpilen från tillstånd 3 till tillstånd 1, men här vore meningslöst att två gånger i rad kolla om bokstaven är A. Bakåtpilen från tillstånd 4 till tillstånd 2 kräver också en förklaring. Om vi har sett ADA och nästa bokstav inte är ett M kan vi i alla fall hoppas att det A vi just sett ska vara början på ADAM. Därför backar vi till tillstånd 2 och undersöker om det möjligen kommer ett D. Reglerna för hur nextvektorn bildas kan sammanfattas så här:
Reglerna kan programmeras i några få satser och ger då den algoritm
för textsökning som uppkallats efter Knuth, Morris och Pratt:
KMP-automat.
Boyer-MooreDå hela texten finns i en vektor kan man istället använda Boyer-Moores metod. Den börjar med att försöka matcha sista tecknet i söksträngen, som ärm
tecken lång.
Om motsvarande tecken i texten inte alls förekommer i söksträngen
hoppar den fram m steg, annars flyttar den fram så att
tecknet i texten passar ihop med sista förekomsten i söksträngen.
Exempel: Vi söker efter TILDA i texten MEN MILDA MATILDA.
MEN MILDA MATILDA
TILDA
TILDA
TILDA
TILDA
MEN MILDA MATILDA
Boyer-Moore är
O(n+m) i värsta fallet, men ca n/m steg om
texten vi söker i består av många fler tecken än dom som ingår
i söksträngen, så att vi oftast kan hoppa fram m steg.
När du skriver Rabin-KarpBeräknar en hashfunktion för söksträngen och jämför med hashfunktionen beräknad för alla avsnitt av längden m i texten. Låt oss söka efter "TILDA" i texten "MEN MILDA MATILDA". Med javashashCode() % 17 får vi hash(TILDA)=6
hash(MEN M)=8
hash(EN MI)=9
hash(N MIL)=3
hash( MILD)=7
hash(MILDA)=0
hash(ILDA )=9
hash(LDA M)=7
hash(DA MA)=16
hash(A MAT)=2
hash( MATI)=1
hash(MATIL)=12
hash(ATILD)=9
hash(TILDA)=6
För att snabba upp beräkningarna använder man hela tiden förra
hashvärdet. Komplexiteten blir
O(nm) i värsta fallet, men i praktiken bara O(n+m).
Man kan läsa mer om algoritmer för textbehandling i kursen 2D1378, Text- och bildbehandling. Sökning på webbenNär man använder en sökmotor, t ex Google, för att hitta webbsidor som innehåller ett visst ord skulle alla ovanstående metoder bli för tidsödande. Där slår man istället upp ordet i ett index som skapats i förväg. Hur det fungerar kan man läsa mer om i kursen 2D1418, Språkteknologi.Reguljära uttryckOm man t ex skulle vilja söka efter lab1, Lab2, eller labb3 så kan man använda ett reguljärt uttryck för att beskriva söksträngen. Ett reguljärt uttryck består av tecken och metatecken som tillsammans utgör ett sökmönster. Metatecken (t ex * och +) har särskild innebörd. Här följer några regler:
[Ll]abb?[1-7] kan användas
för att hitta alla labbvarianter vi eftersökte ovan.
Det finns UNIX-kommandon som använder reguljära uttryck:
Pythonmodulen import re pattern="[Ll]abb?[1-7]" sometext="Lab5, labb 6, labb7 och lab8" print re.findall(pattern,sometext) # Utskriften blir ['Lab5', 'labb7']Bakom kulisserna i re-modulen skapas automater som kan kontrollera
om indata matchar det givna uttrycket.
Tycker du att det här låter intressant? Läs mer i kursen
2D1373, Artificiella språk och syntaxanalys.
Modellering av grafiska gränssnittMånga problem kan modelleras med automater. Objektorienterad programmering lämpar sig väl för att implementera tillstånden.
Exempel:
Objektmodellering och tillståndsprogrammering kan man läsa mer om i kursen 2D1385, Programutvecklingsteknik. |