
Föreläsning 5: Problemträd, breddenförst och djupetförst
ProblemträdEn mycket stor klass av praktiska problem kan beskrivas med problemträd och lösas med trädgenomgång, bredden först eller djupet först. På tentan kommer något sådant problem och det gäller att beskriva lösningsalgoritmen. Laboration 4 går ut på att finna kortaste vägen från fan till gud genom att byta en bokstav i taget och bara använda ord i ordlistan, till exempel så här:fan -> man -> mun -> tun -> tur -> hur -> hud -> gud Problemträd uppkommer ständigt i praktiken. Man brukar kalla startobjektet för urmoder/stamfar och objekten under det för barn. 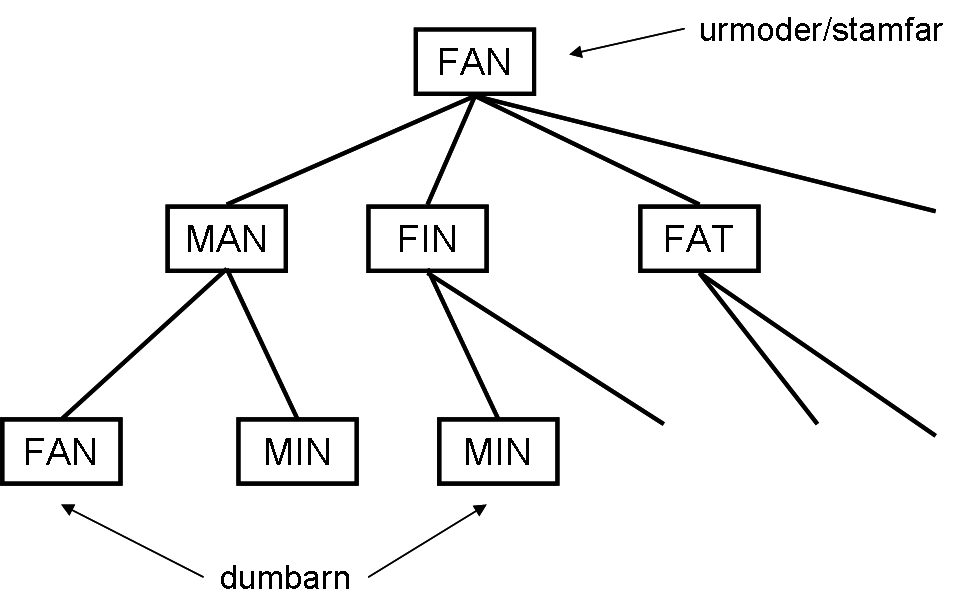
BreddenförstsökningProblemträdets urmoder/stamfar fan har barnen fin, man, far med flera, barnbarnen hin, mun, får osv. Enligt kedjan ovan är gud barnbarnbarnbarnbarnbarnbarn till fan, men gud finns säkert redan tidigare i problemträdet. För att finna den första förekomsten gör man en breddenförstsökning enligt följande.Lägg urmodern/stamfadern som första och enda post i en kö. Gör sedan följande om och om igen: Plocka ut den första ur kön, skapa alla barn till denne och lägg in dom sist i kön. Första förekomsten av det sökta ordet ger kortaste lösningen. Man kan spara in både tid och utrymme om man undviker att skapa barn som är kopior av tidigare släktingar (t ex mans barn fan), så kallade dumbarn. Breddenförstsökningsalgoritmen kan sammanfattas så här.
Breddenförstsökning ger alltid den kortaste lösningen. Ofta är det den man är ute efter. Några andra problemexempel är följande.
Flygresa från Stockholm till Alice SpringsStockholm är stamfar, destinationer med direktflyg från Stockholm blir söner och så vidare. Dumsöner är destinationer man redan "passerat". Breddenförstsökning ger en resa med så få mellanlandningar som möjligt.Lönsam valutaväxlingFinns det någon lönsam växlingskedja av typen 1.00 SEK -> 0.11 EURO -> 0.13 USD -> ... -> 1.02 SEK ? Vi vill ha en algoritm som kan besvara den frågan.Vi antar att alla växlingskurser är kända, t ex 1.00 SEK -> 0.14 USD och 1.00 USD -> 7.05 SEK. En valutanod är ett belopp i en viss valuta. Vi utgår från valutanoden 1.00 SEK och låter den vara urmoder i ett problemträd. Urmoderns döttrar är alla valutanoder som kan åstadkommas med en växling, till exempel 0.14 USD och 16.5 JPY. Dottern 0.14 USD har i sin tur döttrar, däribland 0.987 SEK. Just den är en så kallad dumdotter och kan lugnt glömmas bort, eftersom den är sämre än en tidigare valutanod.
Om man går igenom problemträdet nivå för nivå, dvs generation efter
generation, kanske man till sist stöter på noden 1.05 SEK.
Därmed har man funnit en lönsam växlingskedja och det är bara att sätta igång
och växla så fort som möjligt innan kurserna ändras. För att avbryta
trädgenomgången och hals över huvud återvända till huvudprogrammet kan
man generera ett särfall med
try:
- - - # Om särfallet uppstår här...
except Exception:
- - - # ...teleporteras man hit
Tillsammans med särfallet kan man skicka med ett valfritt objekt, till
exempel ett meddelande, så som exemplet nedan visar.
Om man har en abstrakt kö med metoderna put, get och isempty kan breddenförstsökningen programmeras ungefär så här.
class Node # problemträdspost
amount=1.00 # belopp
currency=1 # valutanummer, SEK=1, USD=2,...
parent=None # förälderpekare
- - - Definition av makechildren och writechain
- - - Inläsning av växlingskurserna
q = Queue()
urmoder=Node()
q.put(urmoder)
try:
while not q.isempty():
makechildren(q.get()) # I makechildren görs raise Exception,kedja
print "Ingen lönsam växling"
except Exception,kedja:
print "Växla fort:",kedja
Metoden makechildren skapar alla barn och lägger sist i kön.
Om man vill bli av med dumdöttrarna kan man ha en global vektor
best med hittills högsta belopp av varje valuta.
Rekursiv djupetförstsökningDjupetförstsökning skiljer sig från breddenförstsökning i två avseenden:
Ett exempel är åttadamersproblemet som innebär att man ska placera åtta damer på ett schackbräde så att ingen dam står på samma vågräta, lodräta eller diagonala linje som någon annan. Problemträdets urförälder är ett tomt bräde. Dom åtta barnen har en dam placerad på översta raden, barnbarnen ytterligare en dam på näst översta raden etc. Problemträdet har djup åtta (fler damer kan vi inte placera ut).
Den första idén man får är ju att representera schackbrädet med
en matris. Men lösningen blir enklare om man använder en vektor,
där varje vektorelement är ett heltal som representerar damens position
på just den raden.
Rekursiv tanke:
# coding:iso-8859-1
n=8
queen=[None]*n
def completePartialSolution(row):
# Fullborda partiell lösning som har damer på rad 0..row-1
if row==n:
for r in range(n):
for col in range(n):
if queen[r]==col: print "D",
else: print "*",
print
print "==============="
return
for col in range(n):
if posOK(row,col):
queen[row]=col
completePartialSolution(row+1)
def posOK(row, col):
# Kolla om damen på rad row kan slås av damerna ovanför
for i in range(row):
if queen[i]==col: return False #rakt ovanför
if queen[i]-col==row-i: return False #snett ovanför
if col-queen[i]==row-i: return False #snett ovanför
return True
completePartialSolution(0)
Djupetförstsökning med stackDjupetförstsökning kan också programmeras som breddenförstsökningen, med den lilla skillnaden att kön byts mot en stack. Här följer några fler exempel på problem som kan lösas med djupetförstsökning.Hitta ut ur labyrintEn välkänd praktisk metod att utforska en labyrint, uppfunnen av den förhistoriska datalogen Ariadne, är att ha ett garnnystan med ena änden fastknuten i startpunkten. Man går så långt man kan, markerar med krita var man varit, går bara outforskade vägar framåt och backar en bit längs snöret när man kör fast. Snöret kan representeras av en stack med dom positioner som snöret för tillfället ringlar igenom.Problemträdet har startpositionen som urförälder, alla positioner på ett stegs avstånd som barn och så vidare. En position som man varit på förut är ett dumbarn.
Luddes portkodssekvensEn teknolog som glömt sin fyrsiffriga portkod tryckte sej igenom alla tiotusen kombinationer så här.000000010002000300040005000600070008000900100011...9999Det kräver fyrtiotusen tryckningar. Men man kan klara sej med bara tiotusentre tryckningar om man har en supersmart sekvens där varje fyrsiffrigt tal förekommer någonstans. Hur ser sekvensen ut? Problemträdets urförälder 0000 har tio barn 00000, 00001,..., 00009, varav det första är ett dumbarn. Breddenförst eller djupetförst? Vi vet att trädet har djupet tiotusen och att alla lösningar är lika långa, därför går djupetförst bra. Men breddenförst skulle kräva biljoner poster! GraferDe problemträd vi tagit upp här är specialfall av grafer.
I breddenförst går vi först igenom alla hörn som ligger en kant från starthörnet, sen alla hörn som ligger två kanter bort osv. Om det finns flera lösningar till problemet stöter vi på den närmaste först (men om vi inte bryter där går vi igenom alla hörnen). Med djupetförst följer vi istället en stig så långt det går via första kanten från starthörnet. När det tar stopp backar vi ett steg (flera vid behov) tills det går att fortsätta framåt igen. I kursen 2D1352 Algoritmer, datastrukturer och komplexitet kan man lära sig mer om grafalgoritmer! |