
Föreläsning 10 - Syntax, rekursiv medåkning
Syntax för formella språkEtt formellt språk är en väldefinierad uppsättning textsträngar som kan vara oändligt stor, till exempel alla Python-program, eller ändligt stor, till exempel alla månadsnamn. Det bästa sättet att definiera ett språk är med en syntax (observera betoning på sista stavelsen!), det vill säga en grammatik. En så kallad kontextfri grammatik kan beskrivas i Backus-Naur-form (BNF).
Exempel: Språket som består av satserna JAG VET, JAG TROR, DU VET
och DU TROR definieras av syntaxen
I syntaxen ovan har vi tre omskrivningsregler.
Varje regel består av ett vänsterled med en icke-slutsymbol
(t ex
Meningar av typen <Mening> ::= <Sats> | <Sats><Konj><Mening> <Konj> ::= ATT | OCHPlötsligt har vi fått en syntax som beskriver en oändlig massa meningar! Syntaxen för programspråk beskrivs ofta i BNF. Så här kan man visa hur Javas tilldelningssatser ser ut: <Assignment> ::= <Identifier> = <Expression> ; <Identifier> ::= <Letter> | <Letter> <Digit> | <Letter> <Identifier> <Letter> ::= a-z | A-Z | _ | $ <Digit> ::= 0-9Duger denna syntax eller behöver den förbättras?
En kompilator fungerar ungefär så här: källkod --> lexikal analys --> syntaxanalys --> semantisk analys --> --> kodgenerering --> målkod
Uppgift: Skriv en BNF-grammatik för vanliga taluttryck med operationerna
Lösning:
<Uttryck> ::= <Term> | <Term> + <Uttryck> | <Term> - <Uttryck>
<Term> ::= <Faktor> | <Faktor> * <Term> | <Faktor> / <Term>
<Faktor> ::= TAL | -<Faktor> | (<Uttryck>)
|
*
/ \
2 ( )
|
+
/ \
3 *
/ \
4 5
Den första delen av sytaxanalysen, att kontrollera om ett program följer
syntaxen kan göras med rekursiv medåkning eller med en stack.
Rekursiv medåkning (recursive descent)Denna metod för syntaxanalys ska ni använda er av i labb 6: Formelkoll!För varje symbol i grammatiken skriver man en inläsningsmetod. Om vi vill analysera grammatiken vi började med behöver vi alltså metoderna:
q.peek().
När något strider mot syntaxen låter vi ett särfall skickas iväg.
Här följer ett program som undersöker om en mening följer vår syntax.
# coding:iso-8859-1
# Syntaxkoll
from queue import Queue
def readmening():
readsats()
if q.peek()==".":
q.get()
else:
readkonj()
readmening()
def readsats():
readsubj()
readpred()
def readsubj():
ord = q.get()
if ord=="JAG": return
if ord=="DU": return
raise Exception,"Fel subjekt:"+ord
def readpred():
ord = q.get()
if ord=="TROR": return
if ord=="VET": return
raise Exception, "Fel predikat:"+ord
def readkonj():
ord = q.get()
if ord=="ATT": return
if ord=="OCH": return
raise Exception, "Fel konjunktion:"+ord
q=Queue()
for ord in raw_input("Skriv en mening:").split():
q.put(ord)
try:
readmening()
print "Följer syntaxen!"
except Exception,msg:
print msg,"före",
while not q.isempty():
print q.get(),
print
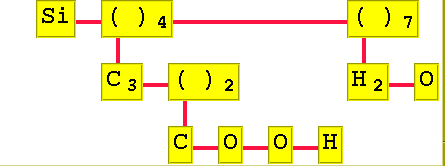
LaborationerI labb 6 ska ni skriva ett program som kollar att molekyler som användaren matar in via tangentbordet följer en syntax. I labb 7 ska ni bygga vidare på programmet från labb 6 så att det även skapar ett syntaxträd (och ritar upp det med hjälp av en färdig grafikmodul,molgrafik.py).
Syntaxträdet är ett allmänt träd där varje nod (motsvarar en ruta i bilden)
kan representeras med ett objekt från klassen Ruta nedan:
class Ruta:
atom="( )"
num=1
next=None
down=None
Molekylen Si(C3(COOH)2)4(H2O)7 får följande utseende:
 Sist i laboration 7 ska ni också beräkna molekylernas vikt (finns även som frivillig uppgift i laboration 6). För att göra det ska ni använda hashtabellen från laboration 5. Syntaxkontroll med stackEtt alternativt sätt att kontrollera om inmatningen följer en syntax är att använda en stack. Som exempel tar vi upp en vanlig källa till kompileringsfel: omatchade parenteser. Så här kan man använda en stack för att hålla reda på parenteserna:
Mer om syntaxanalys kan man lära sig i kursen 2D1373, Artificiella språk och syntaxanalys. |