Exempel: Sprĺket som bestĺr av satserna JAG VET, JAG TROR, DU VET
och DU TROR definieras av syntaxen
<Sats> ::= <Subj> <Pred>
<Subj> ::= JAG | DU
<Pred> ::= VET | TROR
I syntaxen ovan har vi tre omskrivningsregler.
Varje regel bestĺr av ett vänsterled med en icke-slutsymbol
(t ex <Sats> ovan)
och ett högerled som talar om vad man kan ersätta vänsterledet med.
I högerledet fĺr det förekomma bĺde icke-slutsymboler och
slutsymboler (t ex JAG i exemplet ovan).
Tecknet | betyder eller.
Meningar av typen
JAG VET ATT DU TROR ATT JAG VET OCH JAG TROR ATT DU VET ATT JAG TROR
definieras nu sĺ här:
<Mening> ::= <Sats> | <Sats><Konj><Mening> <Konj> ::= ATT | OCHMed hjälp av den rekursiva definitionen av Mening har vi plötsligt fĺtt en syntax som beskriver en oändlig massa meningar!
Syntaxen för programsprĺk beskrivs ofta i BNF. Sĺ här beskrivs Pythons tilldelningssatser i dokumentationen:
<assignment_stmt> ::= (<target_list> "=")+ <expression_list>
<target_list> ::= <target> ("," <target>)* [","]
<target> ::= <identifier>
| "(" <target_list> ")"
| "[" <target_list> "]"
| <attributeref>
| <subscription>
| <slicing>
Man kan förstĺs beskriva syntaxen för BNF i BNF, och det ser ut sĺ här:
<syntax> ::= <regel> | <regel> <syntax> <regel> ::= "<" <regelnamn> ">" "::=" <uttryck> <radslut> <uttryck> ::= <lista> | <lista> "|" <uttryck> <radslut> ::= <RETURTECKEN> | <radslut> <radslut> <lista> ::= <term> | <term> <lista> <term> ::= <slutsymbol> | "<" <regelnamn> ">" <slutsymbol> ::= '"' <text> '"' | "'" <text> "'"
källkod --> lexikal analys --> syntaxanalys --> semantisk analys --> --> kodgenerering --> mĺlkod
lab6.pyc).
Uppgift: Skriv en BNF-grammatik för vanliga taluttryck med operationerna
+ - * /. Den vanliga prioritetsordningen (* och
/ gĺr före + och -) ska gälla mellan
operatorerna. Man ska ocksĺ kunna använda parenteser i taluttrycken.
Rita till sist upp ett syntaxträd för uttrycket 2*(3+4*5).
Lösning:
<Uttryck> ::= <Term> | <Term> + <Uttryck> | <Term> - <Uttryck>
<Term> ::= <Faktor> | <Faktor> * <Term> | <Faktor> / <Term>
<Faktor> ::= TAL | -<Faktor> | (<Uttryck>)
|
*
/ \
2 ( )
|
+
/ \
3 *
/ \
4 5
Den första delen av sytaxanalysen, att kontrollera om ett program följer syntaxen kan göras med rekursiv medĺkning eller med en stack.
readSats()
readSubj()
readPred()
readMening()
readKonj()
q.peek()
som vi har lagt till i klassen WordQueue.
När nĺgot strider mot syntaxen lĺter vi ett särfall skickas iväg.
Här följer ett program som undersöker om en mening följer vĺr syntax.
# Syntaxkoll
from queue import WordQueue
def readMening():
readSats()
if q.peek() == ".":
q.get()
else:
readKonj()
readMening()
def readSats():
readSubj()
readPred()
def readSubj():
ordet = q.get()
if ordet == "JAG":
return
if ordet == "DU":
return
raise Grammatikfel,"Fel subjekt:"+ordet
def readPred():
ordet = q.get()
if ordet == "TROR":
return
if ordet == "VET":
return
raise Grammatikfel, "Fel predikat:"+ordet
def readKonj():
ordet = q.get()
if ordet == "ATT":
return
if ordet == "OCH":
return
raise Grammatikfel, "Fel konjunktion:"+ordet
q = WordQueue()
for ordet in raw_input("Skriv en mening:").split():
q.put(ordet)
try:
readMening()
print "Följer syntaxen!"
except Grammatikfel,msg:
print msg,"före",
while not q.isempty():
print q.get(),
print
[), lägg den pĺ stacken.
]), titta pĺ stacken.
Om stacken är tom eller om den symbol som poppar ut inte matchar slutsymbolen
har vi ett syntaxfel.
Mer om hur det ser ut bakom kulisserna kan man lära sig i kursen DD2377, Maskinnära programmering och datorarkitektur.
I labb 7 ska du bygga vidare pĺ programmet frĺn labb 6 sĺ att det även
skapar ett syntaxträd (och ritar upp det med hjälp av en färdig
grafikmodul, molgrafik.py).
Syntaxträdet är ett allmänt träd där varje nod (motsvarar en ruta i bilden)
kan representeras med ett objekt frĺn klassen Ruta nedan:
class Ruta:
__init__(self):
self.atom = "( )"
self.num = 1
self.next = None
self.down = None
Molekylen Si(C3(COOH)2)4(H2O)7 fĺr följande utseende:
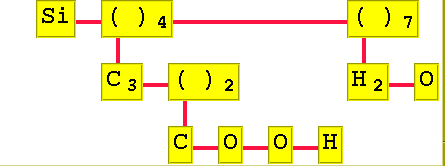
Sist i laboration 7 ska du ocksĺ beräkna molekylernas vikt. För att göra det ska du använda hashtabellen du skrev laboration 5!
Titta pĺ en animation av rekursiv medĺkning