Olika former av kryptering har använts så länge man har velat ha skriftliga hemligheter. Redan dom gamla grekerna hade flera system för kryptering.
Samma effekt kan vi få genom att skriva meddelandet i en mxn-matris och bilda det kodade meddelandet genom att ta varje kolumn i texten. Den som känner till matrisens storlek kan lätt avkoda det. Man brukar skippa mellanslag och skiljetecken för att göra det svårare att knäcka koden.
JAGGÖ MMERP ENGAR NAIDE NGAML AEKENkodas alltså som:
JMENNAAMNAGEGEGIAKGRADMEÖPRELN
En variant är rot13 där man förskjuter varje bokstav 13 steg. Hamnar man utanför alfabetet roterar man runt till början igen.
def rot13(meddelande):
alfabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
kod = ""
for bokstav in meddelande:
index = (alfabet.find(bokstav) + 13) % 26
kod = kod + alfabet[index]
return kod
Om vi skippar ÅÄÖ får vi ett alfabet som består av 26 tecken,
vilket innebär att vi kan använda samma funktion för dekryptering!
rot13("HEMLIGHETER") blir URZYVTURGRE
rot13("URZYVTURGRE") blir HEMLIGHETER
Ännu hemligare blir det om vi slumpar fram en mappning
istället för att flytta fram ett visst antal steg.
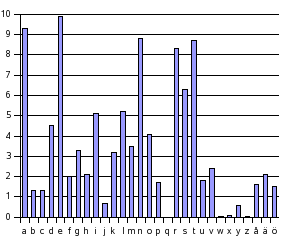
ABCDEFGHIJKLMNOPQRSTUVWXY ||||||||||||||||||||||||| FSXNVDQBCULRHKTPAOMWJEIGYAlla dessa chiffer är dock enkla att knäcka om man har statistik över hur ofta varje bokstav förekommer i det aktuella språket. Så här ser det ut för svenska:
Krypteringsalgoritmen RSA (döpt efter Ron Rivest, Adi Shamir och Leonard Adleman som först publicerade den) löser detta genom att ha en offentlig nyckel och en privat nyckel. Den offentliga nyckeln delar du ut till alla, så att dom kan kryptera meddelanden och skicka till dig, men det är bara du som kan dekryptera med hjälp av den privata nyckeln.
Först måste vi beräkna nycklarna:
Sedan beräknar vi mie modulo n för att få de kodade delarna ci.
Den som vill dekryptera måste känna till d, och kan då få ut det ursprungliga meddelandet genom att beräkna cid modulo n för varje ci.
På University of Illinois har man gjort en demo av RSA, prova gärna!
För att knäcka RSA måste man faktorisera n, dvs lista ut vilka de två stora primtalen p och q är. Det finns ännu ingen algoritm som kan göra detta i polynomisk tid, dvs O(Lk) där L är längden av primtalet och k är en godtycklig konstant, vilket innebär att beräkningen tar för lång tid för att vara praktiskt användbar. Därför räknar man med att RSA i nuläget är oknäckbar för tillräckligt stora primtal.
En fortsättningskurs som bland annat handlar om tillämpningar av kryptering är DD2395 Datasäkerhet. Där får man också lära sig om t ex virus och datajuridik.
Säkerhetsaspekter tas även upp i kursen DD1334 Databasteknik som vissa av er läser redan i vår.
Vi har förstås också kursen DD2448 Kryptografins grunder (men den kräver att man läst DD1352 ADK först).
Vanliga datastrukturer (sorterad array, sökträd, hashtabell) faller alla på något av kraven ovan.
tab.
Den booleska variabeln tab[f(ord)] låter vi vara
sann då ord ingår i ordlistan. Detta ger en snabb, minnessnål
och kodad datastruktur, men den har en stor brist: Om det råkar bli
så att hashfunktionen antar samma värde för ett ord i ordlistan som
för ett felstavat ord så kommer det felstavade ordet att godkännas.
Om hashtabellen exempelvis är fylld till häften med ettor så är sannolikheten
för att ett felstavat ord ska godkännas ungefär 50% vilket är alldeles för
mycket.
tab. I Viggos stavningskontrollprogram Stava
används till exempel 14 olika hashfunktioner
f0(ord),f1(ord),
f2(ord),...,f13(ord).
Ett ord godkänns bara om alla dessa 14 hashfunktioner samtidigt ger
index till platser i tab som innehåller sant.
Uppslagning av ett ord kan då ske på följande sätt:
for i in range(14):
if not tab[f(i, ord)]: return False
return True
Om hashtabellen är till hälften fylld med ettor blir sannolikheten för
att ett felstavat ord godkänns så liten som (1/2)14=0.006%.
Denna datastruktur kallas bloomfilter efter en
datalogiforskare vid namn Bloom. Ett abstrakt bloomfilter har bara
två operationer: insert(x) som stoppar in x i datastrukturen
och isIn(x) som kollar ifall x finns med i datastrukturen.
Programmet Stava kan köras på
webben på http://www.nada.kth.se/stava/
(hjälp finns via webbsidan)
{kind=link}