I en prioritetskö stämplas en prioritet pĺ varje objekt som stoppas in och vid uthämtning fĺr man objektet med högst prioritet.
En abstrakt prioritetskö kan ha föjande anrop.
put(p,x)
x = get()
isEmpty()
put(x).
Hur den dĺ skiljer sej frĺn en stack och
frĺn en vanlig kö ser man av följande exempel.
pq.put(1)
pq.put(3)
pq.put(2)
x = pq.get() # x blir 3
En kö hade skickat tillbaka det först instoppade talet 1;
en stack hade skickat tillbaka det senast instoppade talet, 2;
prioritetskön skickar tillbaka det bästa talet, 3.
I denna prioritetskö betraktar vi största talet som bäst - vi har en sĺ
kallad maxprioritetskö. Det finns förstĺs ocksĺ minprioritetsköer, där
det minsta talet betraktas som bäst.
Prioritetsköer har mĺnga användningar. Man kan tänka sej en auktion där
budgivarna stoppar in sina bud i en maxprioritetskö och auktionsförrättaren efter
"första, andra, tredje" gör pq.get() för att fĺ reda pĺ det
vinnande budet.
För att han ska veta vem som lagt detta bud behövs förstĺs bĺda
parametrarna i pq.put(p,x).
pq.put(bud,person) #person är ett objekt med budgivarens namn och bud
winner = pq.get() #budgivaren med högst bud
tab tolkad som binärträd.
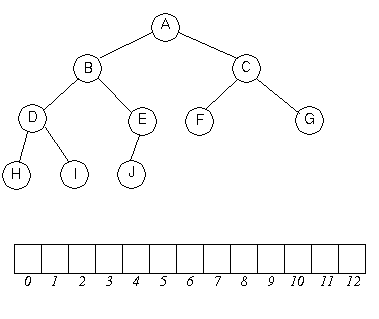 Roten är
Roten är tab[1] (vi använder inte tab[0], dess bĺda barn är
tab[2] och tab[3] osv. Allmänt
gäller att tab[i] har barnen
tab[2*i] och tab[2*i+1].
Trappvillkoret är att föräldern är bäst, dvs varje tal ligger
pĺ tvĺ sämre tal.
Ett nytt tal läggs alltid in sist i trappan. Om trappvillkoret inte blir
uppfyllt, dvs om det är större än sin förälder,
byter förälder och barn plats och
sĺ fortgĺr det tills villkoret uppfyllts. Det här kallas
upptrappning och kan i värsta fall föra det nya talet
hela vägen upp till toppen, alltsĺ tab[1].
Man plockar alltid ut det översta talet ur trappan och fyller igen tomrummet med det sista talet i trappan. Dĺ är inte trappvillkoret uppfyllt, sĺ man fĺr byta talet och dess största barn. Denna nedtrappning upprepas tills villkoret ĺter gäller.
Bĺde put och get har komplexitet log N
om trappan har N element. Nackdelen med trappan är man mĺste
bestämma listans storlek frĺn början.
Här följer en rudimentär implementation av en max-heap:
class HeapNode:
def __init__(self, data, priority):
"""data är det objekt vi vill lagra
priority är nyckelvärdet som används för att jämföra objekten"""
self.data = data
self.priority = priority
class Heap:
# En max-heap
def __init__(self, maxsize):
"""Skapar en lista där vi använder element 1..maxsize"""
self.maxsize = maxsize
self.tab = (maxsize+1)*[None]
self.size = 0
def isEmpty(self):
"""Returnerar True om heapen är tom, False annars"""
return self.size == 0
def isFull(self):
"""Returnerar True om heapen är full, False annars"""
return self.size == self.maxsize
def put(self, data, priority):
"""Lägger in nya data med nyckeln priority i heapen"""
if not self.isFull():
self.size += 1
self.tab[self.size] = HeapNode(data, priority)
i = self.size
while i > 1 and self.tab[i//2].priority < self.tab[i].priority:
self.tab[i//2], self.tab[i] = self.tab[i], self.tab[i//2]
i = i//2
def get(self):
"""Hämtar det största (översta) objektet ur heapen"""
if not self.isEmpty():
data = self.tab[1]
self.tab[1] = self.tab[self.size]
self.size -= 1
i = 1
while i <= self.size//2:
maxi = self.maxindex(i)
if self.tab[i].priority < self.tab[maxi].priority:
self.tab[i],self.tab[maxi] = self.tab[maxi], self.tab[i]
i = maxi
return data.data
else:
return None
def maxindex(self, i):
"""Returnerar index för det största barnet"""
if 2*i+1 > self.size:
return 2*i
if self.tab[2*i].priority > self.tab[2*i+1].priority:
return 2*i
else:
return 2*i+1
heap = Heap(16)
for word in open("folksagor.txt").read().split():
heap.put(word, word)
while not heap.isempty():
print heap.get()
Heapsortanimation frĺn Aucklands universitet.
Det här är exempel pĺ en girig algoritm, där man i varje steg väljer den väg som verkar bäst för stunden, utan att reflektera över vad konsekvenserna blir i längden. Ofta ger giriga algoritmer inte den bästa lösningen, men i just det här fallet fungerar det faktiskt! Algoritmen kallas Dijkstra's algoritm (efter den holländske datalogen Edsger W. Dijkstra) och att den fungerar bevisas i fortsättningskursen DD1352 Algoritmer, datastrukturer och komplexitet.
Exempel 1: Sök billigaste transport frĺn Teknis till
Honolulu. All världens resprislistor finns tillgängliga.
Problemträdets objekt innehĺller en plats, ett pris och en
förälderpekare. Överst i trädet stĺr Teknis med priset noll. Barnen
är alla platser man kan komma till med en transport och priset, till exempel
T-centralen, 20.00. Man söker en Honoluluobjekt i problemträdet.
Med breddenförstsökning fĺr man den resa som har sĺ fĺ transportsteg som
möjligt.
Med bästaförstsökning fĺr man den billigaste resan.
Exempel 2: Sök effektivaste processen för att framställa
en önskad substans frĺn en given substans. All världens kemiska
reaktioner finns tillgängliga med uppgift om utbytet i procent.
Problemträdets objekt innehĺller substansnamn och procenttal. Överst i
trädet stĺr utgĺngssubstansen med procenttalet 100. Barnen är alla
substanser man kan framställa med en reaktion och utbytet, till
exempel C2H5OH, 96%.
Med en max-prioritetskö fĺr man fram den effektivaste process som leder till mĺlet.
Att testa sina program är en självklarhet, annars vet man ju inte om de fungerar. Det är en sak att fĺ sitt program att kompilera, en annan att sak att det verkligen gör det man vill att det ska göra.
Man mĺste testa att programmet fungerar för
Det finns en modul i python - doctest - som kan tolka tester i kodkommentaren. Man kan klistra in en testkörning av funktionen och den kommer att utföras. Här följer ett exempel pĺ get()-funktionen i en köklass (se labb 2).
class Queue:
"En köklass"
# Kod i köklassen
def get(self):
"""
Returnerar och tar bort det som stĺr först i kön.
>>> q = Queue()
>>> q.put(5)
>>> q.put(3)
>>> q.get() == 5
True
""" # """ (html)
# Här börjar koden i funktionen
x = self.first.value
self.first = self.first.next
return x
# Mer kod i köklassen
def _test():
import doctest
doctest.testmod()
if __name__ == "__main__":
_test()
Kör vi funktionen _test() fĺr vi en utmatning som berättar vilka tester som görs. Vore köklassen felaktigt implementerad sĺ get() returnerade nĺgot annat än 5 skulle vi fĺ följande svar:
**********************************************************************
File "queue.py", line 22, in __main__.Queue.get
Failed example:
q.get == 5
Expected:
True
Got:
False
**********************************************************************
1 items had failures:
1 of 4 in __main__.Queue.get
***Test Failed*** 1 failures.
Det behövs mĺnga tester för att testa stora system och alla dessa gĺr inte att skriva i kodkommentarer för dĺ blir inte kommentaren läslig. Istället skriver man egna testklasser som bara har till uppgift att testa en eller flera klasser i systemet. För att testa igenom hela systemet kör man sedan alla testfall i alla testklasser. I python finns ett paket - unittest - som man använder för detta. Exempel:
import unittest
from heap import Heap
class TestSequenceFunctions(unittest.TestCase):
def setUp(self):
self.heap = Heap(8)
def test_put_och_get(self):
# prova att stoppa in tre värden och plocka ut minsta
self.heap.put(1,1)
self.heap.put(3,3)
self.heap.put(2,2)
self.assertEqual(self.heap.get(), 3)
if __name__ == '__main__':
unittest.main()
Ett viktigt skäl till testning är att göra regressionstest, d.v.s. att kontrollera att den befintliga koden inte pĺverkas i oönskad riktning dĺ man tillför eller ändrar nĺgon annanstans. Om systemet är stort medför det ofta att mĺnga tusentals test mĺste göras varje gĺng nĺgot ändras i koden. Att automatisera testningen är nödvändigt.
Odokumenterade tester är värdelösa! Fĺr man under utvecklingen av ett system en felrapport frĺn ett test mĺste man snabbt kunna fĺ veta vad för slags fel det är, helst sĺ noggrant beskrivet som möjligt. All testkod mĺste alltsĺ ocksĺ dokumenteras sĺ det är lätt att felsöka.
Tester dokumenteras ofta i en testmatris (ett stort excelark) där testid, förutsättningar, testet, förväntat resultat och utfall dokumenteras.