Binära sökträdBinära trädEtt binärt träd är en datastruktur som enklast beskrivs med hjälp av rekursion: Ett binärt träd är antingen tomt eller består av en nod (som också kallas trädets rot) och två subträd, det vänstra och det högra subträdet, som båda är binära träd. En nod vars båda subträd är tomma kallas för ett löv. Om p är en nod och q är roten i ett av p:s subträd så säger man att p är förälder till q och att q är barn till p. Två olika noder som har samma förälder kallas syskon. Mängden av förfäder till noden n defineras rekursivt av dessa två regler:
Djupet för en nod är antalet element på vägen från noden till trädets rot. Djupet för ett träd definieras som det största djupet för en nod i trädet. Det tomma trädet har djup 0. Binära sökträdEtt binärt sökträd är ett binärt träd där varje nod innehåller ett värde från en ordnad mängd. För varje nod n i ett binärt sökträd gäller följande invariant:
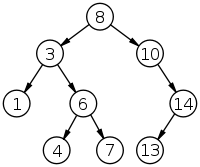
ExempelHär är en bild som visar ett binärt sökträd med 9 noder och djup 4.
Trädets rot har värdet 8. I löven finns värdena 1, 4, 7 och 13. Samtliga noder i rotens vänstra subträd har värden som är mindre än 8, medan noderna i det högra subträdet alla är större än 8. Kontrollera att motsvarande invariant gäller för varje nod i trädet. Några algoritmer för binära trädEtt binärt träd sägs vara välbalanserat om varje nod i trädet har två subträd med ungefär samma antal noder. Man kan visa att ett välbalanserat träd med n noder har ett djup som är O(log n). Om man lyckas hålla ett binärt sökträd välbalanserat så kan man alltså bygga en ordnad datastruktur där de grundläggande operationerna insättning, sökning och borttagning alla har mycket bra tidskomplexitet i värstafall. Det finns många, mer eller mindre komplicerade, strategier för att upprätthålla en god balans i ett binärt sökträd. Några av de mest kända datastrukturerna är:
InordergenomgångOm man vill skriva ut alla värden i ett binärt sökträd i sorterad ordning så behöver man gå igenom trädet i inorder: besök för vänster subträd, sedan roten, och avsluta med att besöka höger subträd. En implementation av denna algoritm blir med nödvändighet rekursiv. Sökning i ett binärt sökträdDet är ganska lätt att implementera sökning i ett binärt sökträd med hjälp av iteration, men som övning visar vi ändå en rekursiv version.Insättning i ett binärt sökträdVi gör insättning i ett binärt sökträd med hjälp av rekursion för att demonstrera hur man kan implementera mer komplicerade algoritmer som ändrar i trädet. Tricket är att deklarera en metod som tar roten till det gamla trädet som parameter och sedan returnerar roten på det nya modifierade trädet. |