
Exempel: Språket som består av satserna JAG VET, JAG TROR, DU VET
och DU TROR definieras av syntaxen
<Sats> ::= <Subj> <Pred>
<Subj> ::= JAG | DU
<Pred> ::= VET | TROR
I syntaxen ovan har vi tre omskrivningsregler.
Varje regel består av ett vänsterled med en icke-slutsymbol
(t ex <Sats> ovan)
och ett högerled som talar om vad man kan ersätta vänsterledet med.
I högerledet får det förekomma både icke-slutsymboler och
slutsymboler (t ex JAG i exemplet ovan).
Tecknet | betyder eller.
Meningar av typen
JAG VET ATT DU TROR ATT JAG VET OCH JAG TROR ATT DU VET ATT JAG TROR
definieras nu så här:
<Mening> ::= <Sats> | <Sats><Konj><Mening> <Konj> ::= ATT | OCHPlötsligt har vi fått en syntax som beskriver en oändlig massa meningar!
Syntaxen för programspråk beskrivs ofta i BNF. Så här kan man visa hur Javas tilldelningssatser ser ut:
<Assignment> ::= <Identifier> = <Expression> ; <Identifier> ::= <Letter> | <Letter> <Digit> | <Letter> <Identifier> <Letter> ::= a-z | A-Z | _ | $ <Digit> ::= 0-9Duger denna syntax eller behöver den förbättras?
En kompilator fungerar ungefär så här:
källkod --> lexikal analys --> syntaxanalys --> semantisk analys --> kodgenerering --> målkod
Java.class).
Uppgift: Skriv en BNF-grammatik för vanliga taluttryck med operationerna
+ - * /. Den vanliga prioritetsordningen (* och
/ går före + och -) ska gälla mellan
operatorerna. Man ska också kunna använda parenteser i taluttrycken.
Rita till sist upp ett syntaxträd för uttrycket 2*(3+4*5).
Lösning:
<Uttryck> ::= <Term> | <Term> + <Uttryck> | <Term> - <Uttryck>;
<Term> ::= <Faktor> | <Faktor> * <Term> | <Faktor> / <Term>;
<Faktor> ::= TAL | -<Faktor> | (<Uttryck>);
|
*
/ \
2 ( )
|
+
/ \
3 *
/ \
4 5
Den första delen av sytaxanalysen, att kontrollera om ett program följer
syntaxen kan göras med rekursiv medåkning eller med en stack.
readsats()
readsubj()
readpred()
readmening()
readkonj()
q.peek().
När något strider mot syntaxen låter vi ett särfall skickas iväg.
Här följer ett program som undersöker om en mening följer syntaxen ovan.
# coding:iso-8859-1
# Syntaxkoll
from queue import Queue
class Grammatikfel(Exception):
#Miniklass för brott mot syntaxen
pass
def readmening():
readsats()
if q.peek()==".":
q.get()
else:
readkonj()
readmening()
def readsats():
readsubj()
readpred()
def readsubj():
ord = q.get()
if ord=="JAG": return
if ord=="DU": return
raise Grammatikfel,"Fel subjekt:"+ord
def readpred():
ord = q.get()
if ord=="TROR": return
if ord=="VET": return
raise Grammatikfel, "Fel predikat:"+ord
def readkonj():
ord = q.get()
if ord=="ATT": return
if ord=="OCH": return
raise Grammatikfel, "Fel konjunktion:"+ord
q=Queue()
for ord in raw_input("Skriv en mening:").split():
q.put(ord)
try:
readmening()
print "Följer syntaxen!"
except Grammatikfel,msg:
print msg,"före",
while not q.isempty():
print q.get(),
print
I labb 6 ska ni bygga vidare på programmet från labb 5 så att det även
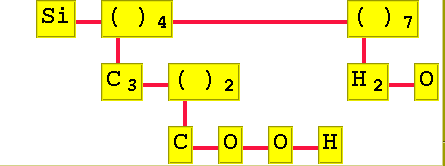
skapar ett syntaxträd (och ritar upp det med hjälp av en färdig grafikmodul, molgrafik.py).
Syntaxträdet är ett allmänt träd där varje nod (motsvarar en ruta i bilden)
kan representeras med ett objekt från klassen Ruta nedan:
class Ruta:
atom="( )"
num=1
next=None
down=None
Zerksis animation av rekursiv medåkning
{), lägg den på stacken.
}), titta på stacken.
Om stacken är tom eller om den symbol som poppar ut inte matchar slutsymbolen
har vi ett syntaxfel.
Mer om det här kan man lära sig i kursen DD2488, Compiler Construction.
A B C D E F G H
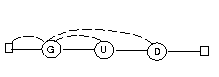
1 1 1 1 2 1 1 1 1 Exempel: Om automaten är i tillstånd 3
2 1 1 1 2 3 1 1 1 och knapp D trycks ner övergår den till
3 1 1 1 2 1 1 4 1 tillstånd 2
Man kan också rita en graf med fyra noder (som representerar tillstånden) och en massa bokstavsmärkta pilar (som visar vilka övergångar som finns).
Här är några fler exempel på vad automater kan användas till:
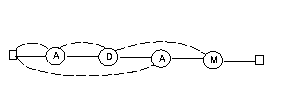
Ett nolltillstånd har skjutits in längst till vänster. Automaten startar emellertid i tillstånd 1, som har ett G i noden. Den tjuvtittar på första bokstaven i bibeln, och om det är ett G läser den G-et och går till höger. Annars följer den bakåtpilen utan att glufsa bokstaven. I nolltillståndet glufsar den alltid en bokstav och går till höger. Koden blir i princip så här, om vi först antar att bokstäverna lästs in i en kö:
i=1 # starttillståndet
while i<4:
if i==0 or q.peek()==gud[i]):
i=i+1
q.get()
else: i=next[i];
}
Här är gud[i] i-te bokstaven i det sökta ordet och
next[i] det tillstånd man backar till från
tillstånd i. Nextvektorn (bakåtpilarna) i vårt exempel blir
i next[i] 1 0 2 1 3 1Om vi i stället söker efter ADAM i bibeln blir Knuth-automaten så här:
Nextvektorn för ADAM blir alltså den här:
i next[i] 1 0 2 1 3 0 4 2För GUD gick bakåtpilen från tillstånd 3 till tillstånd 1, men här vore meningslöst att två gånger i rad kolla om bokstaven är A. Bakåtpilen från tillstånd 4 till tillstånd 2 kräver också en förklaring. Om vi har sett ADA och nästa bokstav inte är ett M kan vi i alla fall hoppas att det A vi just sett ska vara början på ADAM. Därför backar vi till tillstånd 2 och undersöker om det möjligen kommer ett D. Reglerna för hur nextvektorn bildas kan sammanfattas så här:
Reglerna kan programmeras i några få satser och ger då den algoritm
för textsökning som uppkallats efter Knuth, Morris och Pratt: KMP-automat.
Om den sträng vi söker efter är m tecken lång och texten vi söker i
är n tecken lång kräver KMP-sökning aldrig mer än n+m
teckenjämförelser och är alltså O(n+m). Metoden går
igenom texten tecken för tecken - man kan alltså läsa ett tecken
i taget t ex från en fil vilket är praktiskt om texten är stor.
m
tecken lång.
Om motsvarande tecken i texten inte alls förekommer i söksträngen
hoppar den fram m steg, annars flyttar den fram så att
tecknet i texten passar ihop med sista förekomsten i söksträngen.
GUD i bibeln och kollar bara vart
tredje tecken. Så länge det inte är G, U eller D kan vi hoppa vidare.
FÖRSTA MOSEBOKEN 1 I BEGYNNELSEN SKAPADE GUD HIMMEL OCH JORD...
R A O B E 1 _ G (äntligen träff - då får vi jämföra närmare)
GY (tyvärr inget U, så hoppa vidare)
N S _ A D (träff, jämför närmare)
AD (tyvärr inget U, hoppa vidare)
G (träff, jämför närmare)
GUD (succé!)
Boyer-Moore är
O(n+m) i värsta fallet, men ca n/m steg om
texten vi söker i består av många fler tecken än dom som ingår
i söksträngen, så att vi oftast kan hoppa fram m steg.
Ctrl-S för att söka efter en sträng
i Emacs är det Boyer-Moore som används.
hashCode() % 17 får vi hash(TILDA)=6
hash(MEN M)=8
hash(EN MI)=9
hash(N MIL)=3
hash( MILD)=7
hash(MILDA)=0
hash(ILDA )=9
hash(LDA M)=7
hash(DA MA)=16
hash(A MAT)=2
hash( MATI)=1
hash(MATIL)=12
hash(ATILD)=9
hash(TILDA)=6
För att snabba upp beräkningarna använder man hela tiden förra
hashvärdet. Komplexiteten blir
O(nm) i värsta fallet, men i praktiken bara O(n+m).
Metatecken (t ex * och +) har särskild innebörd. Här följer några regler:
[Ll]abb?[1-7] kan användas
för att hitta alla labbvarianter vi eftersökte ovan.
Pythonmodulen re har funktionalitet för reguljära uttryck. Exempel:
import re pattern="[Ll]abb?[1-7]" sometext="Lab5, labb 6, labb7 och lab8" print re.findall(pattern,sometext) # Utskriften blir ['Lab5', 'labb7']Bakom kulisserna i
re-modulen skapas automater som kan kontrollera
om indata matchar det givna uttrycket.
Tycker du att det här låter intressant? Läs mer i kursen
DD2372, Automata and languages.
Exempel:
I många grafiska gränssnitt kan man markera text genom att trycka
ner musknappen och hålla den nedtryckt medan man drar musen över texten.
Det här kan vi se som en automat med ett normaltillstånd och ett
markeringstillstånd, där musknappstryck/släpp ger övergång mellan
tillstånden.
Objektmodellering och tillståndsprogrammering kan man läsa mer om i kursen DD2385, Programutvecklingsteknik.
urllib
re