
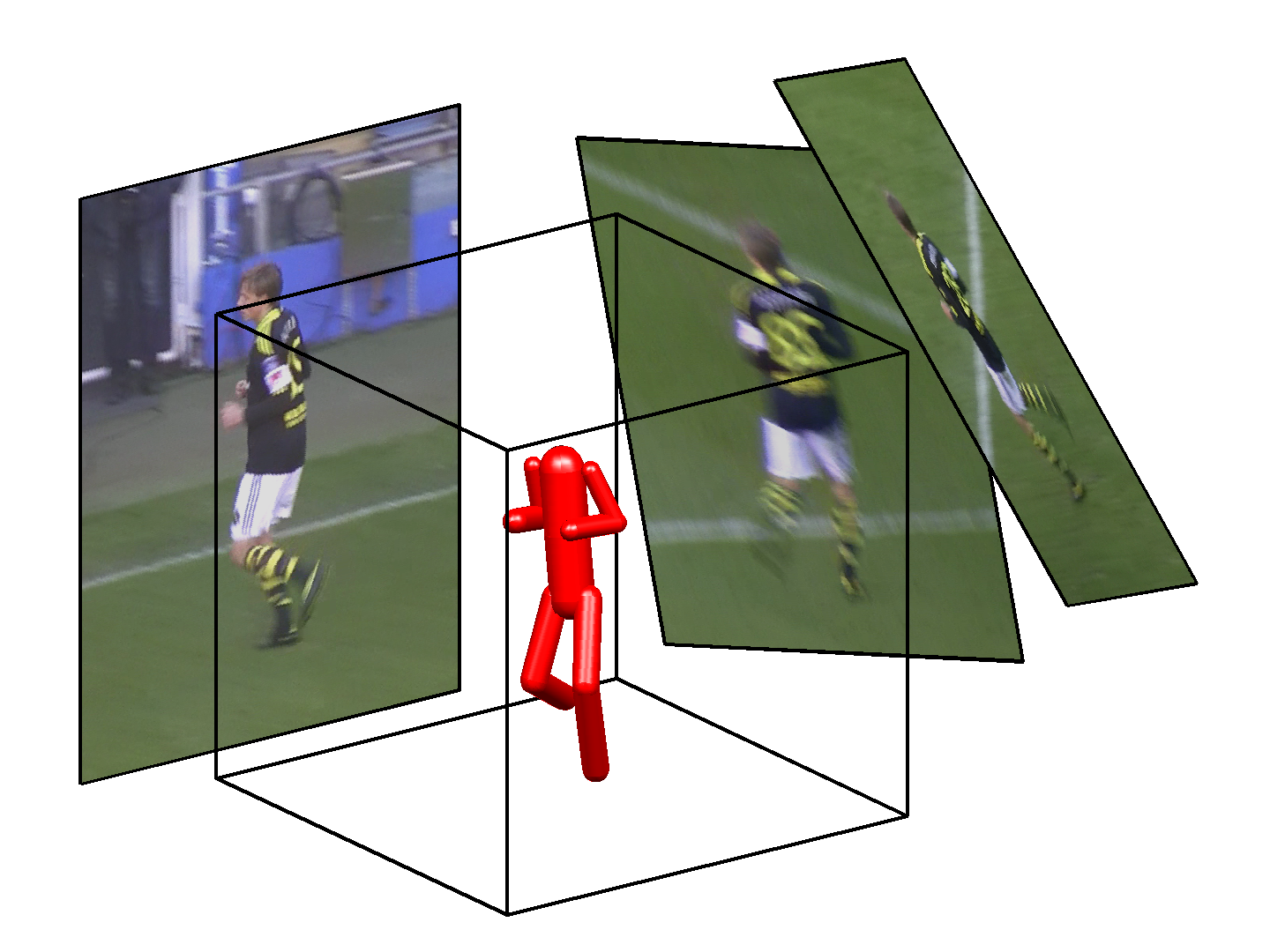
KTH Multiview Football Dataset II
This dataset consists of images of professional footballers during a match of the Allsvenskan league. It consists of two parts: one with ground truth pose in 2D and one with ground truth pose in both 2D and 3D.The dataset may only be used for academic research.
The dataset may not be used for commercial purposes.
If you use the dataset please cite the paper:
Multi-view Body Part Recognition with Random Forests
V. Kazemi, M. Burenius, H. Azizpour, J. Sullivan.
In Proceedings of BMVC 2013.
3D Dataset
- 800 time frames, captured from 3 views (2400 images).
- Views are calibrated and synchronized.
- 3D ground truth pose and orthographic camera matrix for each frame.
- 14 annotated joints.
- 2 different players and two sequences per player.

|

|

|

|
|
Player 1 - Sequence 1 (209MB)
Walking around. |
Player 1 - Sequence 2 (205MB)
Scoring a goal. |
Player 2 - Sequence 1 (241MB)
Running and stepping sideways. |
Player 2 - Sequence 2 (251MB)
Sliding tackle. |
Code showing how to read and visualize the data.
2D Dataset
- 5907 images.
- 2D ground truth pose for each image.
- 14 annotated joints.
- 3 different players.

For even more 2D annotations also see the KTH Multiview Football Dataset I.
Publications
-
Multi-view Body Part Recognition with Random Forests
V. Kazemi, M. Burenius, H. Azizpour, J. Sullivan.
In Proceedings of BMVC 2013.
Awarded the Best Industry Paper Prize.
The first 3900 frames of the 2D dataset was used for training.
For testing the 2D pose estimation the last 2007 frames of the 2D dataset was used.
For testing the 3D pose estimation the first sequence of player 2 was used.
-
3D Pictorial Structures for Multiple View Articulated Pose Estimation
M. Burenius, J. Sullivan, S. Carlsson.
In Proceedings of CVPR 2013.
The second sequence of player 2 was used: the first half for training and the second half for testing.
-
Motion Capture from Dynamic Orthographic Cameras
M. Burenius, J. Sullivan, S. Carlsson.
ICCV Workshop on Dynamic Shape Capture and Analysis 2011.
Explains how we create the ground truth 3D pose and camera matrices from the 2D annotation.