Benchmark of Deep Learning Representations for Visual Recognition |
Lunch time chat on 2014/05/12:
a computer vision scientist: How long does it take to train these generic features on ImageNet?
Hossein: 2 weeks
Ali: almost 3 weeks depending on the hardware
the computer vision scientist: hmmmm...
Stefan: Well, you have to compare the three weeks to the last 40 years of computer vision
BackgroundIn this project we want to investigate the effectiveness of deep learning representations on a wide range of visual recognition tasks/datasets. Some structured output recognition (e.g. pose landmark detection, etc.), RGB-D and/or temporal input are not included at the moment. |
|||||||||
What have been done | |||||||||
- Scope of tasks so far (in the order of getting further away from ImageNet classification task)
|
|||||||||
- Datasets used so far
| |||||||||
| VOC07c: | Pascal VOC 2007 (Object Image Classification) | ||||||||
| VOC12c: | Pascal VOC 2012 (Object Image Classification) | ||||||||
| VOC12a: | Pascal VOC 2012 (Action Image Classification) | ||||||||
| MIT67: | MIT 67 Indoor Scenes(Scene Image Classification) | ||||||||
| VOC07d: | PASCAL VOC 2007 (Object Detection) | ||||||||
| VOC10d: | PASCAL VOC 2010 (Object Detection) | ||||||||
| VOC12d: | PASCAL VOC 2012 (Object Detection) | ||||||||
| VOC11s: | PASCAL VOC 2011 (Object Category Segmentation) | ||||||||
| 200Birds: | UCSD-Caltech 2011-200 Birds dataset (Fine-grained Recognition) | ||||||||
| 102Flowers: | Oxford 102 Flowers (Fine-grained Recognition) | ||||||||
| H3Datt: | H3D poselets Human 9 Attributes (Attribute Detection) | ||||||||
| UIUCatt: | UIUC object attributes (Attribute Detection) | ||||||||
| LFW: | Labelled Faces in the Wild (Metric Learning) | ||||||||
| Oxford5k: | Oxford 5k Buildings Dataset (Instance Retrieval) | ||||||||
| Paris6k: | Paris 6k Buildings Dataset (Instance Retrieval) | ||||||||
| Sculp6k: | Oxford Sculptures Dataset (Instance Retrieval) | ||||||||
| Holidays: | INRIA Holidays Scenes Dataset (Instance Retrieval) | ||||||||
| UKB: | Uni. of Kentucky Retrieval Benchmark Dataset (Instance Retrieval) | ||||||||
--- The results quoted on this page are no longer an accurate reflection of the current state-of-the-art for all the databases we investigated in our 2014 paper. Excitingly, the rate of progress in the field is just too rapid for us, given our resources, to maintain up-to-date numbers. However, we have decided to keep this webpage online as it gives a snapshot of where computer vision methods stood in relation to solving these databases in mid 2014. ---
Results Table
| VOC07c | VOC12c | VOC12a | MIT67 | SUN397 | VOC07d | VOC10d | VOC11s | 200Birds | 102Flowers | H3Datt | UIUCatt | LFW | YTF | Paris6k | Oxford5k | Sculp6k | Holidays | UKB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| best non-CNN results | 70.5 | 82.2 | 69.6 | 64.0 | 47.2 | 34.3 | 40.4 | 47.6 | 56.8 | 80.7 | 69.9 | ~90.0 | 96.3 | 89.4 | 78.2 | 81.7 | 45.4 | 82.2 | 89.3 |
| off-the-shelf ImageNet Model | 80.1[13] 80.1[10] 77.2[1] |
82.7[10] 79.0[6] |
- | 69.0[1] | 40.9[4] | 46.2[2] 46.1[11] 44.9[13] |
44.1[11] | - | 61.8[1] 58.8[4] |
86.8[1] | 73.0[1] | 91.5[1] | - | - | 79.5[1] | 68.0[1] | 42.3[1] | 84.3[1] | 91.1[1] |
| off-the-shelf ImageNet Model + rep learning | - | - | - | 68.9[3] | 52.0[3] | - | - | - | 65.0[4] | - | - | - | - | - | - | - | - | 80.2[3] | - |
| fine-tuned ImageNet Model | 82.42[10] 77.7[5] |
83.2[10] 82.8[5] |
70.2[5] | - | - | 60.9[13] 58.5[2] |
53.7[2] | 47.9[2] | 75.7[12] | - | - | - | - | - | - | - | - | - | - |
| Other Deep Learning Models | - | - | - | - | - | - | - | - | - | - | 79.0[7] | - | 97.35[8] | 91.4[8] | - | - | - | - | - |
References
[*] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner "Gradient-based learning applied to document recognition" Proc. IEEE 1998
[+] K. Fukushima Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position" Biological Cybernetics 1990
[0] A. Krizhevsky, I. Sutskever, G. E. Hinton "ImageNet Classification with Deep Convolutional Neural Networks" NIPS 2012
[1] A. S. Razavian, H. Azizpour, J. Sullivan, S. Carlsson "CNN features off-the-shelf: An astounding baseline for recognition", CVPR 2014, DeepVision workshop
[2] R. Girshick, J. Donahue, T. Darrell, J. Malik "Rich feature hierarchies for accurate object detection and semantic segmentation", CVPR 2014
[3] Y. Gong, L. Wang, R. Guo, S. Lazebnik "Multi-scale Orderless Pooling of Deep Convolutional Activation Features" arXiv report 2014
[4] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, T. Darrell "DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition" ICML 2014
[5] M. Oquab, L. Bottou, I. Laptev and J. Sivic "Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks" CVPR 2014
[6] M. D. Zeiler, R. Fergus, "Visualizing and Understanding Convolutional Networks" arXiv 2013
[7] N. Zhang, M. Paluri, M. Ranzato, T. Darrell, L. Bourdev "PANDA: Pose Aligned Networks for Deep Attribute Modeling" CVPR 2014
[8] Y. Taigman, M. Yang, M. Ranzato, L. Wolf "DeepFace: Closing the Gap to Human-Level Performance in Face Verification" CVPR 2014
[9] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, Y. LeCun "OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks" ICLR 2014
[10] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman "Return of the Devil in the Details: Delving Deep into Convolutional Nets" arXiv 2014
[11] W. Y. Zou, X. Wang, M. Sun, Y. Lin "Generic Object Detection with Dense Neural Patterns and Regionlets" arXiv 2014
[12] S. Branson, G. Van Horn, S. Belongie, P. Perona "Bird Species Categorization Using Pose Normalized Deep Convolutional Nets" arXiv 2014
[13] K. He, X. Zhang, Sh. Ren, J. Sun "Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition" arXiv 2014
[14] H. Azizpour, A. S. Razavian, J. Sullivan, A. Maki, S. Carlsson "From Generic to Specific Deep Representations for Visual Recognition" arXiv 2014
Our People
KTH-CVAP | ||
| Professor. | ||
| Stefan Carlsson | ||
| Dr. | ||
| Josephine Sullivan | ||
| Dr. | ||
| Atsuto Maki | ||
| PhD Student | ||
| Hossein Azizpour | ||
| PhD Student | ||
| Ali Sharif Razavian |
Our Publications

|
A. S. Razavian
,
H. Azizpour
,
J. Sullivan
,
A. Maki
,
C. H. Ek
,
S. Carlsson
""Persistent Evidence of Local Image Properties in Generic ConvNets" arXiv 2014
PDF Abstract. Supervised training of a convolutional network for object classification should make explicit any information related to the class of objects and disregard any auxiliary information associated with the capture of the image or the variation within the object class. Does this happen in practice? Although this seems to pertain to the very final layers in the network, if we look at earlier layers we find that this is not the case. Surprisingly, strong spatial information is implicit. This paper addresses this, in particular, exploiting the image representation at the first fully connected layer, i.e. the global image descriptor which has been recently shown to be most effective in a range of visual recognition tasks. We empirically demonstrate evidences for the finding in the contexts of four different tasks: 2d landmark detection, 2d object keypoints prediction, estimation of the RGB values of input image, and recovery of semantic label of each pixel. We base our investigation on a simple framework with ridge rigression commonly across these tasks, and show results which all support our insight. Such spatial information can be used for computing correspondence of landmarks to a good accuracy, but should potentially be useful for improving the training of the convolutional nets for classification purposes. |
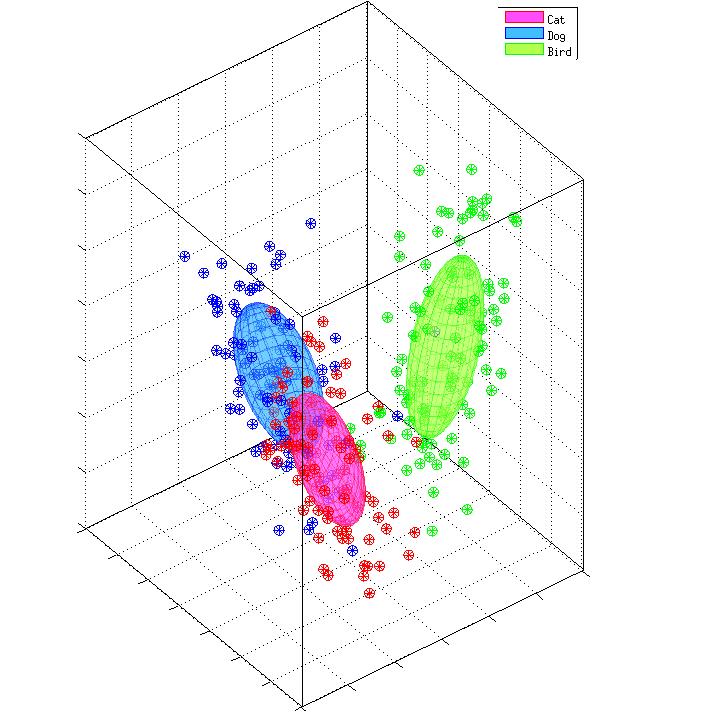
|
[14]
H. Azizpour
,
A. S. Razavian
,
J. Sullivan
,
A. Maki
,
S. Carlsson
""From Generic to Specific Deep Representations for Visual Recognition" arXiv 2014
PDF Abstract. Evidence is mounting that CNNs are currently the most efficient and successful way to learn visual representations. This paper address the questions on why CNN representations are so effective and how to improve them if one wants to maximize performance for a single task or a range of tasks. We assess experimentally the importance of different aspects of learning and choosing a CNN representation to its performance on a diverse set of visual recognition tasks. In particular, we investigate how altering the parameters in a network's architecture and its training impacts the representation's ability to specialize and generalize. We also study the effect of fine-tuning a generic network towards a particular task. Extensive experiments indicate the trends; (a) increasing specialization increases performance on the target task but can hurt the ability to generalize to other tasks and (b) the less specialized the original network the more likely it is to benefit from fine-tuning. As by-products we have learnt several deep CNN image representations which when combined with a simple linear SVM classifier or similarity measure produce the best performance on 12 standard datasets measuring the ability to solve visual recognition tasks ranging from image classification to image retrieval. |

|
[1]
A. S. Razavian
,
H. Azizpour
,
J. Sullivan
,
S. Carlsson
"CNN features off-the-shelf: An astounding baseline for recogniton", CVPR 2014, DeepVision Workshop, Columbus, US
PDF Best Paper Runner-up Award Abstract. Recent results indicate that the generic descriptors extracted from the convolutional neural networks are very powerful. This paper adds to the mounting evidence that this is indeed the case. We report on a series of experiments conducted for different recognition tasks using the publicly available code and model of the OverFeat[9] network which was trained to perform object classification on ILSVRC13. We use features extracted from the OverFeat[9] network as a generic image representation to tackle the diverse range of recognition tasks of object image classification, scene recognition, fine grained recognition, attribute detection and image retrieval applied to a diverse set of datasets. We selected these tasks and datasets as they gradually move further away from the original task and data the OverFeat[9] network was trained to solve. Astonishingly, we report consistent superior results compared to the highly tuned state-of-the-art systems in all the visual classification tasks on various datasets. The results strongly suggest that features obtained from deep learning with convolutional nets should be the primary candidate in most visual recognition tasks. |
Resources
- Reproducability crash scripts: The following scripts are provided only for reproducing results reported in [1]. The clean github project for reproducing all the results including the whole pipeline will be released later.
- scripts and features to reproduce the results of [1] on MIT67 dataset (Scene Image Classification): 1.3G
- jittered images to reproduce the features above on MIT67 dataset (Scene Image Classification): 3.6G
- script and features to reproduce the results of [1] on Holidays dataset (Instance Retrieval): 165M
- jittered images to reproduce the features above on Holidays dataset (Instance Retrieval): 119M
- Pierre Sermanet slides: http://cs.nyu.edu/~sermanet/papers/Deep_ConvNets_for_Vision-Results.pdf
- OverFeat[9] implemenation of CNN: http://cilvr.nyu.edu/doku.php?id=software:overfeat:start
- Caffe[4] implementation of CNN: http://caffe.berkeleyvision.org/
- Alex Krizhevsky[0] implementation of CNN: https://code.google.com/p/cuda-convnet/
Acknowledgement
- We would like to gratefully acknowledge the support of NVIDIA Corporation with the donation of multiple Tesla K40 GPUs used for this research. This would have been impossible without their generous donation.
- We would like to thank the following people for their helpful comments: Dr. Atsuto Maki, Dr. Pierre Sermanet, Dr. Ivan Laptev, Dr. Ross Girshick, and Dr. Relja Arandjelovic
Contact
contact Hossein Azizpour and/or Ali S. Razavian via the e-mail address: familyname@kth.se if you see any inconsistencies in the web-page (tables, references, resources, etc.) or have questions/remarks with precise information of the content to be updated or modified. Thanks!Links
Computer Vision GroupComputer Vision and Active Perception Laboratory