|
def urvalssortera(data):
n = len(data)
for i in range(n):
minst = i
for j in range(i+1,n):
if data[j] < data[minst]:
minst = j
data[minst],data[i] = data[i], data[minst]
|
Urvalssorteringsanimation frÍn Hong Kongs universitet.
Bubbelsortanimation frÍn universitetet i Oldenburg.
Komplexiteten ðr i allmðnhet O(N2) men den ðr lite snabbare ðn urvalssortering i praktiken eftersom en flytt ðr snabbare ðn ett byte. F—r att sortera in ett nytt vðrde i en redan sorterad lista ðr insðttning bðst.
|
def insattningssortera(data):
n = len(data)
for i in range(1, n):
varde = data[i]
plats = i
while plats > 0 and data[plats-1] > varde:
data[plats] = data[plats-1]
plats = plats - 1
data[plats] = varde
|
Animation av insðttningssortering frÍn Indian Institute of Technology i Kanpur.
def quicksort(data):
sista = len(data) - 1
qsort(data, 0, sista)
def qsort(data, i, j):
pivotindex = (i+j)/2
data[pivotindex], data[j] = data[j], data[pivotindex]
k = partitionera(data, i-1, j, data[j])
data[k], data[j] = data[j], data[k]
if k-i > 1:
qsort(data, i, k-1)
if j-k > 1:
qsort(data, k+1, j)
def partitionera(data, v, h, pivot):
while True:
v = v + 1
while data[v] < pivot:
v = v + 1
h = h -1
while h != 0 and data[h] > pivot:
h = h -1
data[v], data[h] = data[h], data[v]
if v >= h: break
data[v], data[h] = data[h], data[v]
return v
Komplexiteten blir i allmðnhet O(N log N). Det beror pÍ att man kan dela listan pÍ mitten log N gÍnger. Exakt hur snabb den ðr beror pÍ hur man avg—r vilka vðrden som ska vara damer. Om man tar det f—rsta vðrdet i listan och utnðmner det och alla mindre vðrden till damer, sÍ blir Quicksort mycket lÍngsam f—r redan nðstan sorterade listor! Det bðsta ðr att ta ut tre vðrden - det f—rsta, det sista och nÍgot i mitten - och lÍta det mellersta vðrdet bestðmma vad som ðr damer. Det kallas median-of-three. Man kan visa att komplexiteten dÍ blir 1.4 N log N i genomsnitt.
Quicksortanimation frÍn Aucklands universitet.
def mergesort(data):
if len(data) > 1:
mitten = len(data)/2
vensterHalva = data[:mitten]
hogerHalva = data[mitten:]
mergesort(vensterHalva)
mergesort(hogerHalva)
i, j, k = 0, 0, 0
while i < len(vensterHalva) and j < len(hogerHalva):
if vensterHalva[i] < hogerHalva[j]:
data[k] = vensterHalva[i]
i = i + 1
else:
data[k] = hogerHalva[j]
j = j + 1
k = k + 1
while i < len(vensterHalva):
data[k] = vensterHalva[i]
i = i + 1
k = k + 1
while j < len(hogerHalva):
data[k] = hogerHalva[j]
j = j + 1
k = k + 1
Mergesortanimation frÍn North Carolina State University.
Inom datalogi anvðnds detta uttryck f—r att beskriva en l—sningsmetod dðr man delar upp ett problem i tvÍ eller flera delproblem och l—ser dessa var f—r sig. Delproblemen l—ses enklast med rekursion!
Quicksort och mergesort ðr tvÍ exempel pÍ divide-and-conquer-principen.
| 3 | 4 | 3 | 3 | 5 | 3 | 5 | 3 | 5 | 4 | 5 | 3 | 4 |
| 3 | 3 | 3 | 4 |
I en prioritetsk— stðmplas en prioritet pÍ varje objekt som stoppas in och vid uthðmtning fÍr man objektet med h—gst prioritet.
En abstrakt prioritetsk— kan ha f—jande anrop.
put(p,x)
x = get()
isEmpty()
put(x).
Hur den dÍ skiljer sej frÍn en stack och
frÍn en vanlig k— ser man av f—ljande exempel.
pq.put(1)
pq.put(3)
pq.put(2)
x = pq.get() # x blir 3
En k— hade skickat tillbaka det f—rst instoppade talet 1;
en stack hade skickat tillbaka det senast instoppade talet, 2;
prioritetsk—n skickar tillbaka det bðsta talet, 3.
I denna prioritetsk— betraktar vi st—rsta talet som bðst - vi har en sÍ
kallad maxprioritetsk—. Det finns f—rstÍs ocksÍ minprioritetsk—er, dðr
det minsta talet betraktas som bðst.
Prioritetsk—er har mÍnga anvðndningar. Man kan tðnka sej en auktion dðr
budgivarna stoppar in sina bud i en maxprioritetsk— och auktionsf—rrðttaren efter
"f—rsta, andra, tredje" g—r pq.get() f—r att fÍ reda pÍ det
vinnande budet.
F—r att han ska veta vem som lagt detta bud beh—vs f—rstÍs bÍda
parametrarna i pq.put(p,x).
pq.put(bud,person) #person ðr ett objekt med budgivarens namn och bud
winner = pq.get() #budgivaren med h—gst bud
tab tolkad som binðrtrðd.
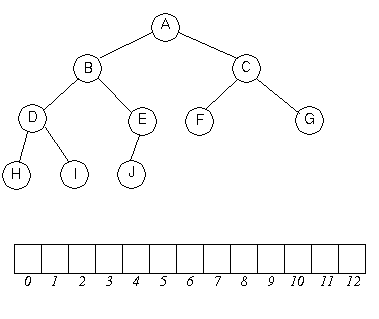 Roten ðr
Roten ðr tab[1] (vi anvðnder inte tab[0], dess bÍda barn ðr
tab[2] och tab[3] osv. Allmðnt
gðller att tab[i] har barnen
tab[2*i] och tab[2*i+1].
Trappvillkoret ðr att f—rðldern ðr bðst, dvs varje tal ligger
pÍ tvÍ sðmre tal.
Ett nytt tal lðggs alltid in sist i trappan. Om trappvillkoret inte blir
uppfyllt, dvs om det ðr st—rre ðn sin f—rðlder,
byter f—rðlder och barn plats och
sÍ fortgÍr det tills villkoret uppfyllts. Det hðr kallas
upptrappning och kan i vðrsta fall f—ra det nya talet
hela vðgen upp till toppen, alltsÍ tab[1].
Man plockar alltid ut det —versta talet ur trappan och fyller igen tomrummet med det sista talet i trappan. DÍ ðr inte trappvillkoret uppfyllt, sÍ man fÍr byta talet och dess st—rsta barn. Denna nedtrappning upprepas tills villkoret Íter gðller.
BÍde put och get har komplexitet log N
om trappan har N element. Nackdelen med trappan ðr man mÍste
bestðmma listans storlek frÍn b—rjan.
Hðr f—ljer en rudimentðr implementation av en max-heap:
class HeapNode:
def __init__(self, data, priority):
"""data ðr det objekt vi vill lagra
priority ðr nyckelvðrdet som anvðnds f—r att jðmf—ra objekten"""
self.data = data
self.priority = priority
class Heap:
# En max-heap
def __init__(self, maxsize):
"""Skapar en lista dðr vi anvðnder element 1..maxsize"""
self.maxsize = maxsize
self.tab = (maxsize+1)*[None]
self.size = 0
def isEmpty(self):
"""Returnerar True om heapen ðr tom, False annars"""
return self.size == 0
def isFull(self):
"""Returnerar True om heapen ðr full, False annars"""
return self.size == self.maxsize
def put(self, data, priority):
"""Lðgger in nya data med nyckeln priority i heapen"""
if not self.isFull():
self.size += 1
self.tab[self.size] = HeapNode(data, priority)
i = self.size
while i > 1 and self.tab[i//2].priority < self.tab[i].priority:
self.tab[i//2], self.tab[i] = self.tab[i], self.tab[i//2]
i = i//2
def get(self):
"""Hðmtar det st—rsta (—versta) objektet ur heapen"""
if not self.isEmpty():
data = self.tab[1]
self.tab[1] = self.tab[self.size]
self.size -= 1
i = 1
while i <= self.size//2:
maxi = self.maxindex(i)
if self.tab[i].priority < self.tab[maxi].priority:
self.tab[i],self.tab[maxi] = self.tab[maxi], self.tab[i]
i = maxi
return data.data
else:
return None
def maxindex(self, i):
"""Returnerar index f—r det st—rsta barnet"""
if 2*i+1 > self.size:
return 2*i
if self.tab[2*i].priority > self.tab[2*i+1].priority:
return 2*i
else:
return 2*i+1
heap = Heap(16)
for word in open("folksagor.txt").read().split():
heap.put(word, word)
while not heap.isempty():
print heap.get()
Heapsortanimation frÍn Aucklands universitet.
Det hðr ðr exempel pÍ en girig algoritm, dðr man i varje steg vðljer den vðg som verkar bðst f—r stunden, utan att reflektera —ver vad konsekvenserna blir i lðngden. Ofta ger giriga algoritmer inte den bðsta l—sningen, men i just det hðr fallet fungerar det faktiskt! Algoritmen kallas Dijkstra's algoritm (efter den hollðndske datalogen Edsger W. Dijkstra) och att den fungerar bevisas i fortsðttningskursen DD1352 Algoritmer, datastrukturer och komplexitet.
Exempel 1: S—k billigaste transport frÍn Teknis till
Honolulu. All vðrldens resprislistor finns tillgðngliga.
Problemtrðdets objekt innehÍller en plats, ett pris och en
f—rðlderpekare. øverst i trðdet stÍr Teknis med priset noll. Barnen
ðr alla platser man kan komma till med en transport och priset, till exempel
T-centralen, 20.00. Man s—ker en Honoluluobjekt i problemtrðdet.
Med breddenf—rsts—kning fÍr man den resa som har sÍ fÍ transportsteg som
m—jligt.
Med bðstaf—rsts—kning fÍr man den billigaste resan.
Exempel 2: S—k effektivaste processen f—r att framstðlla
en —nskad substans frÍn en given substans. All vðrldens kemiska
reaktioner finns tillgðngliga med uppgift om utbytet i procent.
Problemtrðdets objekt innehÍller substansnamn och procenttal. øverst i
trðdet stÍr utgÍngssubstansen med procenttalet 100. Barnen ðr alla
substanser man kan framstðlla med en reaktion och utbytet, till
exempel C2H5OH, 96%.
Med en max-prioritetsk— fÍr man fram den effektivaste process som leder till mÍlet.