![]()
Laboration 5 - Livsträdet
Boken Object-oriented programming in Java av Martin Kalin har tidigare använts som kursbok pĺ DD2385. I boken finns ett program som grafiskt presenterar filkatalogträd med hjälp av en avancerad swingkomponent, JTree. Koden (nĺgot lite modifierad) finns här: DirTree.java. Kompilera den och provkör med
java DirTree
som ska visa trädet under den katalog du stĺr i. Försök ocksĺ till exempel
java DirTree ~henrik/labbar
som visar trädet för den angivna katalogen. Kolla att klickningar fungerar och att man kan fĺ veta detaljer om en fil om
Show details är markerad.
Ett minimalt livsträd
Denna första förberedande uppgift är att modifiera programmet sĺ att det visar ett helt annat träd, nämligen livsträdet. I trädets rot ska det stĺLiv och roten ska ha tre barn, Växter,
Djur och Svampar. Dessa ska senare i sin tur
kunna innehĺlla ordningar, underordningar, familjer, släkten och arter.
Börja med nĺgra smĺ ändringar för att bekanta dig med programmet:
- I rotnoden ska ordet "Liv" stĺ, inte katalognamnet.
- I metoden
private void buildTree()suddar du allt och skriver nya satser som gör följande.- Tillverka en nod
childpĺ samma sätt som rotnoden men med textenVäxter. - Addera den till trädmodellen med
rootsom förälder. Nĺgra rader längre ner i koden ser du hur det gĺr till.
- Tillverka en nod
- Gör likadant med djur och svampar.
- Kompilera, kör och kolla att det ser bra ut.
Ett rekursivt livsträd
I stället för att tillverka noderna för hand ska du läsa in livsträdet frĺn filen Liv.xml (finns även som Liv.txt). En liten testversion av filen ser ut sĺ här, finns ocksĺ i LillaLiv.txt. Om du har problem med svenska bokstäverna, använd följande versioner: Life.txt, Life.xml och TinyLife.txt som är utan prickar och ringar.<Biosfär namn="Liv"> är allt som fortplantar sej <Rike namn="Växter"> kan inte förflytta sej </Rike> <Rike namn="Djur"> kan förflytta sej </Rike> <Rike namn="Svampar"> är varken djur eller växter </Rike> </Biosfär>Förutom nodens namn finns i filerna ocksĺ en nivĺ (t ex Rike) och en förklarande text men för dom finns ingen plats i klassen
DefaultMutableTreeNode.
Skriv därför en egen subklass t.ex. MyNode med
String-variablerna level och text sĺ att all
data frĺn livträdsfilerna fĺr plats.
Skriv sedan en rekursiv metod som läser filen och skapar trädet, t.ex.
enligt följande:
root=readNode(starttagg); //Läser XML-filen och skapar hela trädetInnan den här metoden anropas bör man ha läst den första vänstervinkeln och starttaggen ur filen.
readNode läser data för noden
och skapar ett nodobjekt.
 När sluttagg nĺs
ska den läsas och jämföras med starttaggen. Om de är olika ska
nĺgot Exception kastas eller ĺtminstone ska en utskrift göras
och programmet stanna. Normalt returneras den skapade noden.
Ett sätt att genomföra filläsningen och bygga upp trädet förklaras
pĺ nĺgon föreläsning, troligen nr 9 eller 10.
Det gĺr att göra läsningen av filen pĺ mĺnga sätt, var inte "lĺst" av
metodförslaget ovan! Det är självklart
tillĺtet att ha flera samarbetande metoder. Det är ocksĺ tillĺtet
att ha nĺgra data (t.ex. senaste inlästa rad frĺn filen) globala
(dvs instansvariabler) och tillgängliga för alla rekursiva metodanrop.
När sluttagg nĺs
ska den läsas och jämföras med starttaggen. Om de är olika ska
nĺgot Exception kastas eller ĺtminstone ska en utskrift göras
och programmet stanna. Normalt returneras den skapade noden.
Ett sätt att genomföra filläsningen och bygga upp trädet förklaras
pĺ nĺgon föreläsning, troligen nr 9 eller 10.
Det gĺr att göra läsningen av filen pĺ mĺnga sätt, var inte "lĺst" av
metodförslaget ovan! Det är självklart
tillĺtet att ha flera samarbetande metoder. Det är ocksĺ tillĺtet
att ha nĺgra data (t.ex. senaste inlästa rad frĺn filen) globala
(dvs instansvariabler) och tillgängliga för alla rekursiva metodanrop.
Liksom i det ursprungliga programmet DirTree ska man kunna ange filnamn
efter exekveringskommandot
java LifeTree livfil
och om inget namn anges ska programmet ta filen Liv.xml.
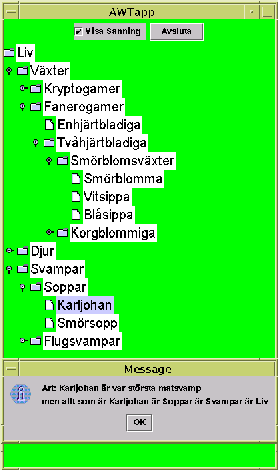
Detaljupplysningar om livet
I det ursprungliga programmet fĺr man filupplysningar om "Show details" förkryssas. I ditt program ska man i stället fĺ se den förklarande texten, till exempelArt: Mĺs gillar Vaxholmsbĺtar.
Fixa sĺ att showDetails(TreePath p) lägger ut denna text
i sin JOptionPane.
Läsning frĺn textfil
Görs enklast med klassenScanner:
Scanner sc = new Scanner(new File("infil.txt"));
new File(...) kan generera ett FileNotFoundException
som mĺste hanteras men om det gick bra att hitta filen kan man sedan
läsa radvis med sc.nextLine().
Krav pĺ programmet
- Indatafil med godtycklig storlek ska klaras av. Programmet fĺr inte förutsätta att att nĺgon nod har ett fast antal barn eller att trädet har ett visst djup.
- Rekursion ska användas när filen läses men det är inte
nödvändigt att följa anvisningarna ovan i detalj med
readNode(). - Programmet ska kontrollera att starttagg och sluttagg stämmer överens men behöver inte identifiera andra typer av fel i indatafilen.
Filformat m.m.
- Programmet fĺr förutsätta att indatafilen är formaterad
sĺ som exemplen, alltsĺ att filen är radindelad med en
"tagg" per rad som exempelfilerna och att det är exakt ett blanktecken
mellan nivĺn och ordet namn
(
<Biosfär namn="Liv">) samt inga blanktecken alls pĺ andra ställen utom i den förklarande texten i slutet av raderna. - Det är tillĺtet att läsa filen radvis, dvs att lĺta programmet hämta in en hel rad frĺn filen vid varje läsning. Alternativet är att läsa ett tecken i taget vilket gör uppgiften svĺrare.
Redovisning
Kör programmet med den större infilen och demonstrera alla funktioner. Glöm inte att be om handledarens signatur pĺ kvittensbladet när han/hon är nöjd med er redovisning!
Extrauppgift (liten!):
Ordna sĺ att man förutom grundinformationenArt: Mĺs gillar Vaxholmsbĺtar
ocksĺ fĺr hela kedjan av namn utskriven
pĺ formen men allt som är Mĺs är Fĺglar är Djur är Liv.
Användbar metod i TreePath är
getLastPathComponent(). I
DefaultMutableTreeNode
och därmed i
MyNode finns metoden getParent().
Det finns även andra metoder som löser uppgiften.