Datastrukturen Heap
Som ni kanske har märkt så blir uppgifterna i IOI och BOI
svårare för varje år, vilket kanske kan kännas
lite tungt. Skräckexemplet var väl schackspringaruppgiften
Knights i BOI 2001 där man skulle översätta problemet
till vertex-cover i en bipartit graf, använda "Hungarian theorem"
för att överföra den minimala "vertex cover" till
maximala matchningen och sedan lösa detta problem med
Hopcroft-Karp's algoritm, den bästa nu kända algoritmen.
Som tur är har kravet på att kunna komplicerade
datastrukturer inte följt samma utveckling som för
algoritmer. Detta är bra eftersom datastrukturer ofta är
ännu svårare än algoritmer att tänka ut
själv, och dessutom tar de ofta lång tid att skriva och
är allmänt tråkiga. Men trots allt har kraven ökat
lite sedan jag började skriva träningssidan,
så jag tänkte åtminstone ta upp en datastruktur,
heapen.
Detta är en av få datastrukturer som jag har använt
för
att lösa tävlingsuppgifter. Framför allt är det en
enkel princip, vilket gör att om man förstår hur den
fungerar
och har implementerat den någon gång så tar den bara
en kvart att skriva sedan.
Den främsta användningen av en heap är som prioritetskö.
Antag t.ex. att de små kölapparna på Posten
är försedda med slumptal istället och att den person med
högst nummer får hjälp först. Hur ställer man
folk på ett smidigt sätt så att den som först ska
försöka köpa frimärken (förgäves)
står först i
kön? Det enklaste borde väl vara att hålla kön
sorterad
och när det kommer in en person placera denne på rätt
ställe
i kön enligt numret på hans lapp.
Tyvärr är det inte lika enkelt att göra i en dator,
åtminstone inte effektivt. Man vill ju helst inte gå igenom
alla personers
lappar så fort det kommer in en ny person, utan trevligare vore
om det räckte med säg t.ex. 2-logaritmen av antalet lappar.
Visserligen kan man använda sig av binärsökning
(alltså
jämföra med mittpersonen och sedan välja rätt halva
och fortsätta så) eftersom kön är sorterad. Detta
ger just log (2) n
jämförelser (där n = antalet lappar). Men när man
sedan ska ställa in
personen på rätt ställe måste man ju flytta alla
bakomvarande personer i kön ett steg bakåt, alltså kan
man behöva gå igenom hela arrayen och flytta element. Aha,
tänker
man då, man kan ju använda en länkad lista
istället
så går det snabbt att flytta in personen i kön. Men
då
kan man å andra sidan inte använda binärsökning
längre
eftersom man inte har tillgång till mittpersonen. Har ni
läst
Moment 22?
Det finns faktiskt inget riktigt enkelt sätt att hålla
kön sorterad, man får använda sig av binära
sökträd som är ganska kluriga att balansera och inte
så roliga att skriva på programmeringstävlingar. Men
om vi går tillbaka till ursprungsproblemet så behövde
vi egentligen inte ha hela kön sorterad utan bara veta vem som
står först på tur. Då kan man använda sig
av en heap istället, för där går både
insättning av element och borttagning av det högsta
elementet på O(log n) tid, där O(log n)
innebär att man kan hitta en konstant c så att
exekveringstiden understiger c log n för alla fall med
tillräckligt stora n. Om
man skriver C++ finns det en sådan prioritetskö inbyggd i
STL, men den har begränsningen att man inte kan ändra numret
på lapparna för dem som redan står i kön.
Därför
är det bra att kunna skriva sin egen heap.
Heapens struktur
En heap är egentligen ett binärt träd (se
figur
nedan till vänster), d.v.s. en slags graf där varje nod har
högst två barn . Varje nod innehåller ett värde
som är det vi är intresserade av. Den översta noden (som
saknar förälder ) kallas för rot och
noderna utan barn kallas för löv. En heap är alltid balanserad
, d.v.s. skillnaden i avstånd mellan roten och två olika
löv är högst ett. Detta innebär alltså att en
rad i trädet fylls helt innan man börjar på nästa
rad. Detta gör att trädet kan sparas i en array så att
varje element i arrayen motsvarar en nod i trädet på det
sätt
som visas i vänstra figuren nedan.
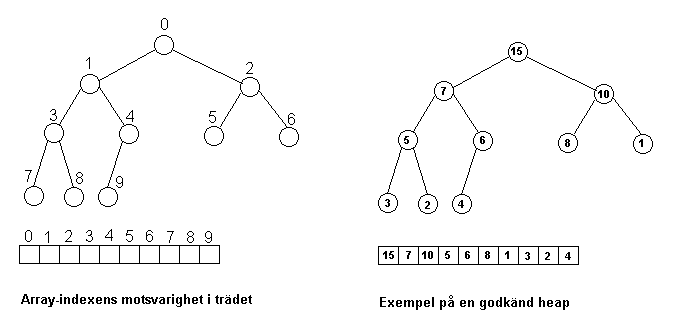
Men än så länge har vi inte gjort något
särskilt. En heap skulle också kunna lagras med hjälp
av pekare mellan noderna, det skulle bara bli lite knöligare. Det
som är speciellt med en heap är följande egenskap
(exempel finns i figuren ovan till höger):
Varje nod har högre värde än sina barn. (Eller
minst lika högt om värdena kan vara lika)
Om man sedan tänker rekursivt så innebär det
också att varje nod har högre värde än alla sina
ättlingar, d.v.s. barnbarn o.s.v. Det högsta värdet i en
heap finns alltså i roten, så rotpersonen ska komma
först till postkassan. Sedan uppstår dock ett problem,
eftersom vi inte vet något om vilket av barnen, vänster
eller höger, som har högst värde. Däremot vet vi ju
att var och en av dem i sin tur är rot för en godkänd
heap. Så vi gör ett trick (GETMAX, källkod i C ). Först flyttar vi upp
det element som ligger längst bak i arrayen till toppen, eftersom
vi då inte har förstört de två
heaparna. Vi minskar storleken på heapen eftersom ett element har
försvunnit,
och sedan anropar vi proceduren HEAPIFY på den nya roten.
( källkod i C )
HEAPIFY(i)
Förutsätter att A är en heap utom möjligen att A[i]
är mindre än något av sina barn. Om så är
fallet:
*Byt plats på A[i] och största barnet
*Kör HEAPIFY på detta barn.
Efter denna rekursiva procedur så är A en heap igen och
tidsåtgången är bara O(log n) eftersom
heapträdets höjd är ungefär log n.
Den andra operationen vi måste ha för en heap är INSERT
( källkod i C ). Först
läggs den nya noden in på den första lediga platsen i
heapen och storleken ökas med 1. Problemet som då kan
uppstå är att värdet av den nya noden är
större än dess förälder. Men då byter vi bara
plats på dessa, så har vi förskjutit problemet ett
steg uppåt i
trädet. Om det insatta värdet är större än den
nya förälderns så byter vi plats igen och detta kan
fortsätta tills vi kommit till roten och där är
problemet garanterat löst
eftersom den inte har någon förälder.
Dessa funktioner är i princip det enda som behövs för
att sköta en heap. Ibland behöver vi dock kunna ändra
på värdena av noder som redan finns i heapen. Ifall
värdet ökas fungerar denna ändring precis som INSERT,
man flyttar alltså ett eventuellt
förälder-barn-problem uppåt i trädet
tills det löser sig. Om värdet minskas anropas istället
HEAPIFY som flyttar problemet neråt istället. I
båda
dessa fall gäller det dock att veta var i heapen en given nod
befinner
sig. Vanlig sökning kan nämligen INTE göras effektivt i
en
heap, det tar O(n) exekveringstid. Lösningen är
naturligtvis att man har någon slags lista där man sparar
platsen i heapen
för varje nod. Denna lista måste då bearbetas
parallellt
med själva heapen så några rader måste
läggas
till i funktionerna. Testa detta genom att lösa t.ex. Speed Limits.
Prioritetskö i STL
Det är väldigt lätt att implementera
postkön med STL:
#include <queue>
#include <vector>
#include <iostream>
int main() {
int pnum;
priority_queue <int, vector<int>, less<int> > pq;
while(1) {
cout << "Antal väntande: " << pq.size();
cout << ". Ny persons nummer (0 betjänar en
person) : ";
cin >> pnum;
if(pnum == 0) {
if(pq.empty()) break;
cout << "Betjänar " << pq.top() <<
'\n';
pq.pop();
}
else pq.push(pnum);
}
return 0;
}
Funktionerna size, empty, top, pop och
push förklarar väl sig själva, det intressanta
är
deklarationen av kön med priority_queue som ska ha tre
klasser
som "template-argument" (ursäkta min terminologi, jag skriver
helst
C-kod). Det ska gå att ha färre sådana argument men
det
verkar inte fungera i gnu. Det första argumentet är typen
för
varje "nod" i trädet, i detta fall sparar vi endast nodens värde
(kölappsnumret) men det kunde ju ha varit en klass med namn,
favoritmaträtt
o.s.v. för de väntande personerna. Det andra argumentet
är
typen av container som man vill använda. Denna
måste innehålla
funktioner som t.ex. push_back och pop_back och jag
ser ingen
direkt anledning att använda något annat än vector
, vilket är en array som är dynamisk så att den
växer
själv när den blir full. Template-argumentet till vector ska
naturligtvis
vara samma som nodtypen. Det tredje argumentet är ett s.k.
funktionsobjekt
som talar om hur två noder ska jämföras med varandra. I
detta
enkla exempel kan man använda de färdiga klasserna less<int>
(placerar den högsta noden i roten) eller greater<int>
(placerar den lägsta noden i roten). Om man till exempel har
strängar i noderna får man skriva ett eget
jämförelse-funktionsobjekt på följande sätt:
class greater_string {
public:
int operator() (char* s1, char* s2) { return strcmp(s1, s2)
> 0; }
};
Om man har mer komplicerade klasser i noderna är det i
jämförelseobjektet man får tala om vilket fält som
är värdet, d.v.s. det som ska jämföras.
struct person {
char* name;
int key;
};
class greater_person {
public:
int operator() (person& p1, person& p2) { return
p1.key > p2.key; }
};
Jag är själv inte så hemma på STL, men det
verkar trevligt (grundläggande om STL kan man hitta t.ex.
här , dock något gammalt). Synd bara att
prioritetskön har gjorts som en svart låda, man kan inte se
vart i heapen ett insatt objekt tar
vägen, och det skulle behövas om man ska kunna implementera
funktioner
av typen DECREASE_KEY som alltså ändrar värdet av en
viss
nod som redan ligger i heapen. Funktionen DECREASE_KEY behövs i
både
Dijkstras algoritm för Kortaste vägen
och Prims algoritm för Minsta uppspännande
trädet . Tyvärr är de underliggande
heap-funktionerna push_heap och pop_heap lika intetsägande,
så slutsatsen är att för dessa viktiga algoritmer kan
man ändå inte använda STL-prioritetskön.
Tävlingsuppgifter
Förutom de två självklara övningsobjekten
Dijkstra's och Prim's algoritmer, som tål att implementeras
för sin egen
skull, kan jag ge följande problem vars lösning ni kan hitta
i
t.ex. Introduction to Algorithms eller klura ut själva
(svårt
att bevisa att det blir optimalt).
Huffman encoding
Antag att du får en lång text samt en
frekvenstabell, d.v.s. antalet gånger varje bokstav
förekommer i texten. Du ska nu försöka komprimera texten
så mycket som möjligt,
men med begränsningen att varje bokstav fortfarande ska motsvaras
av
en bitsträng, t.ex. 01001 för R o.s.v. Det du kan spara plats
på är alltså att låta de vanliga
bokstäverna kodas med korta bitsträngar och de ovanliga med
längre bitsträngar.
Om t.ex. A förekommer 9 gånger, B 5 gånger, C 4
gånger och D 1 gång är en optimal lösning
A = 0, B = 11, C = 101, D = 100
vilket ger 34 bitar för hela texten jämfört med 38 ifall
varje bokstav hade kodats med två bitar. Notera att när 0
betyder A så får naturligtvis ingen annan bokstavskodning
börja
med 0. Skriv ett effektivt program med komplexiteten O(n log n)
som
bestämmer en optimal lösning för n olika
bokstäver
givet frekvenstabellen.
Tillbaka