Föreläsning 5: Binära sökträd, abstraktion, forts rekursion från förra föreläsningenAbstraktionAbstrakta datatyper Det är ofta praktiskt att beskriva vilka operationer man vill kunna göra på sina data utan att behöva tänka på hur operationerna ska implementeras (dvs hur programkoden ska se ut). En datastruktur som beskrivs på detta sätt kallas för en abstrakt datatyp. En abstrakt datatyp
>>> dict.values() [12332, 231444, 53231] >>> dict.keys() ['kalle', 'beata', 'cecilia']Om man kodar mot gränssnittet istället för implementationen så kan man ändra den interna representationen i efterhand. StackEn stack fungerar som en trave tallrikar - det man lägger överst på stacken är det som kommer att tas bort först. För en abstrakt stack finns följande operationer:
class Stack:
push()
pop()
isEmpty()
Binärträd och allmänna trädStack och kö är två viktiga datastrukturer man kan bygga med en länkad lista. Med två referenser i varje objekt kan man emellertid bygga mer intressanta träd, till exempel ett som beskriver en symfoni-orkesters sammansättning.
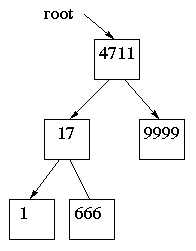
Rekursiva tankar för binärträdAlgoritmer för binärträd blir ofta enklast med en rekursiv tanke. Fråga: Hur många objekt finns det i trädet? Rekursivt svar: Antalet objekt i vänsterträdet plus antalet objekt i högerträdet plus 1. ...men ett tomt träd har 0 objekt. Följande metod gör att antal(root) blir 5 för vårt träd.
def antal(p) :
if (p == None) : return 0
else : return antal(p.left) + antal(p.right) + 1
Binära sökträdI vårt exempelträd ligger små tal till vänster och stora tal till höger. När det är på det sättet har man ett binärt sökträd, så kallat eftersom det går så snabbt att söka reda på ett objekt i trädet. Låt oss säga att vi söker efter 666. Vår algoritm blir följande
Abstrakta sökträdEtt binärt sökträd med en ordlista bör ha åtminstone tre metoder
class Tree:
def exists(word): # ... Returnerar true om ordet finns i trädet
def insert(word): # ... Sorterar in ett nytt ord i trädet
def printTree(): # ... Skriver ut hela trädet
Binära träd blir lätt obalanserade. Ett sätt att får någorlunda balanserade träd är att efter insättning kontrollera om grenen är obalanserad och i så fall byta plats på noderna och/eller roten. Dessa träd ingår inte i kursen men den intresserade kan läsa vidare om t ex AVL-träd eller röd-svarta träd.
Sökträd med informationDet är sällan man nöjer sej med att veta att en söknyckel finns i databasen; oftast vill man att sökningen ska ge tillbaka information om det sökta. Sökmetoden getInfo(key) blir likadan som exists men returnerar nod.info i stället för true/false. Trädet kommer att fungera som pythons dictionary. Trädstrukturer är hierarkiska och sådana datastrukturer är mycket vanliga. T.ex.
|